@khaAk (boa äh, kannst Du bitte ein bisschen auf Interpunktion, Konjunktiv und Substantiv-Großschreibung achten? Ich tue mich echt schwer, Deine Texte zu lesen.)
Ich werde in Zukunft mich verbessern!
")
That said ... Ganz so trivial scheint die Sache mit dem WMMA nicht zu sein.
Zunächst mal ein Hinweis auf einen recht speziellen "hacky workaround" aus dem CachyOS-Forum zu FSR 4.1 auf RDNA 3 - wenn man mal herumexperimentieren möchte (proof of concept (Hans-Kristian Arntzen ist auch involviert):
So I believe I have gotten FSR4 on RDNA3 working with vanilla Wine and thought to share how it all works. I figured I would post my findings to help other non-proton folk use FSR4 on RDNA3 cards without all the mystery behind magical environment variables and scripts that only work with Proton...

discuss.cachyos.org
Selbst verständlich, wie funktioniert denn sonst ROCm auf den RDNA 3 GPUs?
ROCm nutzt für die Compiler (LLVM) folgende befehlsätze:
Im frameworks ROCm (z. B. in nativem HIP C++ oder OpenCL) werden diese Befehle nicht direkt als Assembler-Text, sondern nutzt dafür vordefinierte C++-Funktionen (die sogenannten Intrinsics) oder die offizielle rocWMMA-Bibliothek verwenden bzw. angesprochen. (ausgeführt)
Wenn der Compiler (LLVM) den Code für RDNA 3 übersetzt, erzeugt er für die Matrix-Kerne spezifische Befehle, die alle mit "v_wmma" beginnen. Die genaue Endung hängt vom Datenformat ab:
Für FP16 (Standard): v_wmma_f32_16x16x16_f16
Für BF16: v_wmma_f32_16x16x16_bf16
Für FSR 4.1 müsste folgendes verwendet werden:
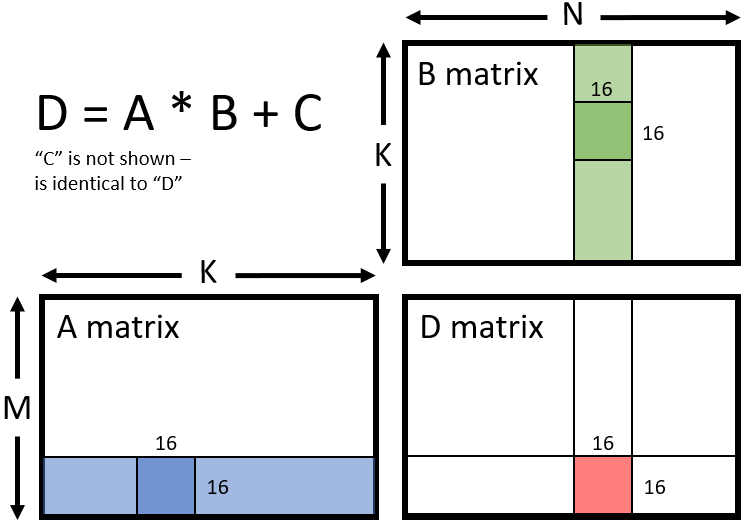
Für INT8 (Das FSR 4.1 Format): V_WMMA_i32_16x16x16_iu8
Der Befehl sagt den Matrix-Kernen: „Nimm eine 16x16-Matrix aus vorzeichenlosen 8-Bit-Ganzzahlen (iu8), multipliziere sie und addiere das Ergebnis in ein 32-Bit-Integer-Register (i32).“
Genau dieser Befehl fehlt im FSR 4.1 Code für RDNA 3. (Siehe Gibhub von AMD)
Stattdessen findet man im (AMD-Open-GPU-Github) dort nur die herkömmlichen v_dot4_i32_i8-Vektorbefehle, die die Matrix-Hardware komplett links liegen lassen. (Sie werden nicht genutzt)
Wenn AMD FSR 4.1 sauber für RDNA 3 programmiert hätte, müsste in den kompilierten Shadern genau dieser
v_wmma_i32_16x16x16_iu8-Befehl auftauchen. Aber dieser Befehl kommt mal nicht vor!
AMDs FSR 4.1 kompiliert seine mathematischen Berechnungen je nach erkannter Hardware-ID in unterschiedliche Shader-Pfade.
Schaut man in die Shader-Dateien für die
INT8-Inferenz, sieht man, dass dort standardmäßige
Dot-Product-Intrinsics der Shader-Language genutzt werden (wie dot4add_i8pack in HLSL). Beim Kompilieren für RDNA 3 übersetzt dieser die Daten dann auf die ALUs-Befehlsatz der Shader.
Dieser Befehl wird von AMDs offiziellem
ISA (Instruction Set Architecture) Manual explizit auf den
Vektor-ALUs (SIMD) der normalen Compute Units ausgeführt. Ein echter Matrix-Core-Befehl müsste im Code über spezielle Wave-Matrix-Intrinsics laufen und mit "V_WMMA" beginnen und kompiliert werden, was hier für RDNA 3 schlicht nicht implementiert ist.
D.h in der Code Basis von FSR 4.1 von AMD auf dem Gibhub werden die Ki-Kerne nicht verwendet,
wäre das der Fall hätten die RDNA 3 GPUs ca 4-8 % mehr leistung. Es werden nur die Shader der ALUs zur Berechnung verwendet. Das ist leider kein Scherz!
Ich hoffe meine ausführung war verständlich.
Fun Fakt:
Würde AMD die KI-Kerne über die V_WMMA-Befehle füttern, würde folgendes passieren:
Die klassischen Rasterizer-Shader (ALUs) der RDNA 3 müssten die Matrix-Mathematik für das FSR 4.1 nicht mehr zusätzlich mitschleppen. (Mehr Leistung)
Diese Rechenleistung stünde sofort wieder für die normale Spiele-Grafik (Geometrie, Beleuchtung, Effekte) zur Verfügung. Der Verzicht auf die KI-Kerne (Matrix-Cores) im FSR 4.1 GitHub-Code kostet - allen - RDNA3 GPUs direkt Gaming-Performance. Das ist leider kein Scherz.
Da die Matrix-Kerne physisch parallel im Chip sitzen, würde die KI-Berechnung fast zeitneutral im Hintergrund ablaufen. Der typische Performance-Einbruch, den Tester / Spieler beim Wechsel von FSR 3.1 auf FSR 4.1 auf RDNA-3-Karten messen, wäre praktisch eliminiert bzw ca. 1-4% Hoch. AMD hat leider den leichten Weg genommen.
Und - ja - man müsste noch mal Arbeit hinein "Buttern" damit es funktioniert, AMD hat es - quasi - den Leuten wie von OptiScaler überlassen. Mal schauen ob AMD es noch nach implemmentiert...
Meine Hoffungungen sind allerdings sehr gedrückt.
Du kannst es hier nach schauen;
The main repository for the FidelityFX SDK. Contribute to GPUOpen-LibrariesAndSDKs/FidelityFX-SDK development by creating an account on GitHub.

github.com
Grüße






")



