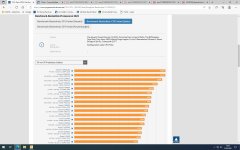
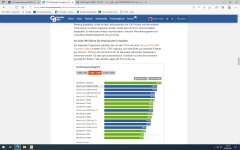
Der Stromverbrauch von Caches ist relativ niedrig, wie der 5800X3D mal wieder eindeutig beweist. Der Rest stimmt aber um so mehr: Wie schon mehrfach vorgerechnet dürfte ein 5800X3D für AMD ähnlich teuer wie ein 5950X sein, der im gleichberechtigten Schnitt über Spiele und Anwendungen viel mehr Leistung und Effizienz bietet. Nur in Spielen, die schnell durch Speicherlatenzen ausgebremst werden, lohnt sich der Monster-Cache einigermaßen. Aber selbst hier würde ich schätzen, dass AMD den 5800X3D mit einer geringeren Marge als den 5800X, also letztlich auch über preissenkende Maßnahmen verkauft. Wäre der Mehraufwand voll eingepreist worden, wäre die CPU auch für Spieler weitaus weniger attraktiv.
Das ist so schlicht und ergreifend nicht richtig/wahr, was du hier schreibst.
Zum einen kannst du uns gerne mal die Rechnung zeigen, wo ein 5800X3D genauso teuer ist für AMD wie ein 5950X. Diesbezüglich gab es nämlich keine einzige Rechnung die das bestätigt.
Und zum anderen habt ihr selbst eine News zum Milan-X veröffentlicht, wo die Preisunterschiede zum normalen Milan 15% betragen und man gleichzeitig 60% in bestimmten Anwendungen bekommt. Was eher darauf schließen lässt, dass AMD sich noch eine extra Marge aus den Produkten holt.
Hier wird permanent der Fehler gemacht, dass Cache innerhalb eines CPUdesigns mit dem 3D-Cache gleichgesetzt wird und das ist einfach nur Käse. Ersterer führt nämlich in der Tat zu höheren Kosten, da dadurch die CPU Fläche zunimmt und weniger DIEs auf einen Wafer passen. Jedoch ist das hier eben nicht der Fall, egal ob mit oder ohne 3D-Cache es purzeln immer genausoviele Ryzen DIEs vom Wafer.
Die entscheidende Frage ist also, was kostet der extra 3D-Cache in der Herstellung? Von der Fläche her ist er deutlich kleiner wie ein Ryzen DIE, geht man also von der gleichen Yieldrate (korrigiert mich, aber bei reinem Speicher ist die in der Regel relativ hoch bei ausgereiften Prozessen und das haben wir in dem Fall) aus, so purzeln deutlich mehr 3D-Cache Speichersteine aus nem Wafer wie Ryzen DIEs. Ergo hätten wir da schonmal deutlich geringere Kosten.
Um es in Zahlen auszudrücken 81mm² zu 41mm², wie viel da pro Wafer mehr rausfallen darf dann gerne jemand anders ausrechnen
")
Dann wäre noch die Frage zu klären, was das Verfahren von TSMC kostet um beides zu vereinigen? Dazu hab ich kein belastbares Zahlenmaterial gefunden.
Also hilft an der Stelle nur ein Blick in AMDs Bilanzen, die eine stetig höhere Marge ausweisen, woraus sich vor allem auf Blick mit Milan-X ableiten lässt, dass AMD hier mindestens genauso hohe Margen einfährt wie mit Milan, tendenziell höher. (Weil es keinen Grund gibt Milan-X zu verramschen)
Und solange wir nicht wissen, was TSMC für das Verfahren berechnet kann man auch keine genaue Aussage treffen. Dass AMD also der 3D-Cache extrem teuer kommt, ist eine reine Annahme von dir und anderen Usern, für die es keinerlei Zahlenmaterial gibt.
Ansonsten darfst du das hier gerne mal im Detail vorrechnen und die Annahme auch mal konkret bestätigen.






")
")


