Vielleicht keine so dumme Idee, 2022 gleich auf 3nm zu gehen, anstatt auf 5nm.
Aus Kostengesichtspunkten könnte es besser sein, anstatt wie AMD immer wieder zur nächstbesseren Prozessorgröße zu gehen. Mal eine neue Generation zu überspringen machen ja auch viele Endkunden, warum dann nicht mal die Hersteller?
")
In diesem Kontext hier (Desktop/Gaming) passt die Jahreszahl nicht; das ist zu früh für 3 nm. TSMCs Prozess (N3) soll laut offizieller Planung erst im 2HJ22 in die HVM überführt werden und dann werden Hersteller üblicherweise mit kleinen Chips starten, d. h. das wäre bei Intel bestenfalls eine Mobile-CPU.
Darüber hinaus ist es auch nicht sonderlich wahrscheinlich, dass sich Intel dermaßen die Marge zerschießen wird, einerseits durch die externe Fertigung und dann noch, indem man auf den aktuellsten, teuersten Node aufspringt. Zudem muss man auch abwarten ob TSMC die Planung einhalten kann, denn zuletzt gab es Gerüchte zu Problemen in der 3nm-Prozessfertigung bei TSMC (und auch bei Samsung).
Intel würde in 2022/23 wohl eher den N5(P) verwenden und zudem soll es noch einen weiteren, zweifellos ebenfalls kostengünstigeren Zwischenschritt geben mit dem N4, ebenfalls einer 5nm-Weiterentwicklung, die ebenso bis Ende 2022 in die HVM überführt werden soll und ebenso wahrscheinlicher ist, als der N3. (
Letztere würden für Intel wohl bestenfalls ab 2023 in Verbindung mit Granite Rapids SP infrage kommen ... bei den Consumer-Produkten hätte eine derartige externe Fertigung zu so früher Stunde einen zu großen Einfluss auf die Marge.)
Und AMD springt ja nicht immer zur nächsten Prozessgeneration. Die fertigen seit 2018 weitestgehend unverändert im N7. Einzig Navi10 sagt man nach im N7P gefertigt zu werden, während RDNA2, Zen3 inkl. APUs und die Konsolen-SoCs weiterhin im N7 gefertigt werden, d. h. hier ist man recht effizient unterwegs, indem man den über die Zeit günstiger werdenden Wafer-Preis mitnimmt und auf einen (wenn auch nur kleinen) Node-Sprung komplett verzichtet. Schätzungsweise erst im 2HJ21 wird AMD einen Half-Node-Sprung auf den N6 machen, voraussichtlich mit Zen3+ was ebenfalls ein kostengetriebenes Thema ist und die APUs in 2022 sollen angeblich weiterhin auf diesem Design und damit dem N6 basieren (während erst das Zen4-Chiplet im nächsten Jahr auf den N5(P) wechselt).
Wenn möglich, würde mich Xmedia Record interessieren.
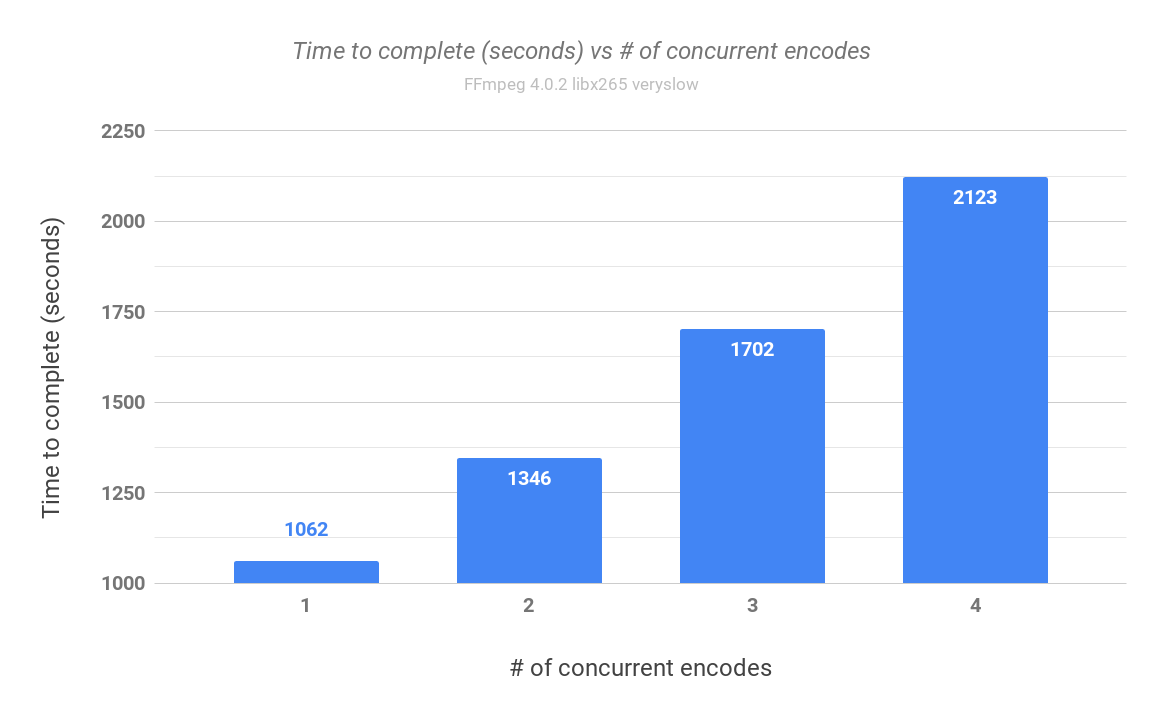
Da ist mir aufgefallen, dass das Programm beim X264 Codec nur 16 Threads verwendet.
Kann das Programm nicht mehr?
"
x264 currently has an internal limit on the number of threads set at 128, realistically you should never set it this high."
Zu beachten ist aber, dass die Kernskalierung mit zunehmender Zahl schelchter wird, was schlicht daran liegt, dass die Threads gewisse Abhängigkeiten untereinander haben, was dem Ganzen Grenzen setzt.
Ab einer hohen Kernzahl ist es sinnvoller mehrere, unterschiedliche Streams parallel zu rendern. Wo der Grenzwert bei x264, weiß ich nicht. Interessant hierzu:
This story was first published on my blog — https://www.singhkays.com/blog/x265-128-core-scaling-4k-hevc-hdr-azure-vm/

singhkays.medium.com
Ob die Werte grob auf x264 übertragbar sind, wird man austesten müssen; der Encoder
könnte sich aufgrund anderer Algorithmen und einer schlechteren Implementaiton auch gänzlich anders verhalten und möglicherweise deutlich früher "einknicken".
Ja bitte gerne

Bin eh schon auf die esten Tests zu AV1 encoding gespannt.
Hoffe da geht noch weniger Dateigröße bei beinahe unverändertem Bild
Natürlich werden die Dateien kleiner; das ist doch Sinn und Zweck eines neuen Codecs.
")
Die stärkere Kompression geht hier jedoch zu Lasten des deutlich höheren Rechenaufwandes bei der Komprimierung ... aktuell ist je nach Ansprüchen die Nutzung von AV1 kein Spaß.
Beispielsweise Anfang Februar 2019 benötigte Intels hochoptimierter SVT-AV1 für die 4K-10Bit-Echtzeitkodierung ein System mit 56 Xeon-Kernen und 48 GiB RAM.
Wer das heute selbst austesten will, kann sich einen aktuellen
ffmpeg-Build herunterladen, der mittlerweile neben dem Referenzencoder libaom-av1 auch eine Version des freien rav1e-Encoders enthält, der von Videolan zusammen mit Mozilla und der Xiph-Community entwickelt wird. Gegenüber H.265/HEVC bzw. in dem Falle dann eher x265 werden die Fps aber beträchtlich in den Keller gehen.
*) Das lizenzpflichtige H.266 (alias VVC) scheint gar noch etwas besser als AV1 kodieren zu können.
**) Als grober Vergleich auf einem Vierkerner, FullHD 1min mit Letterbox, Car Chase, ffmpeg 4.3.1
- x264 : auf rd. 10000 kbit, rd. 42 s bei etwa 95 % Auslastung
- x265: cbr20, ca. rd. 9900 kbit, rd. 123 s bei etwa 95 % Auslastung
- libaom-av1: Referenzencoder, abgebrochen, die ersten 0,75 s (!) nach 9 min bei im Mittel nur 40 % Auslastung
- librav1e: abgebrochen, die ersten 3,0 s nach ca. 4,5 min Renderzeit bei im Mittel 20 % Auslastung
Das ist also derzeit auf der CPU nicht wirklich spaßig und da hilft auch kein 16-Kerner wirklich. Zum einen Ist der Stand des librav1e noch nicht ausreichend gut und parallelisiert noch schlecht, wobei das Projekt zwischenzeitlich aber schon weiter sein dürfte, denn die ffmpeg-Version ist aus 3Q20. Ein Kernproblem ist jedoch, dass die Rechenlast schlicht beträchtlich ansteigt. Beispielsweise das Fraunhofer-Institut geht für ihren H.266 um den Faktor 10 im Vergleich zu H.265/HEVC aus (und von "nur" dem Faktor 10 sind die obigen Encoder in dem jeweiligen Zustand aber selbst noch weit entfernt.)

")






.gif "sm_B-) :-)")