Shader Skalieren sehr wohl mit der Anzahl
GPu sind seriell die einzige frage die sich stellt wo ist das cpu limit.
Ausgenommen man hat ne 16bit arch wie amd mit HD2000 Hd3000 HD4000 HD5000 HD 6000 ~40% shader Auslastung Treiber bedingt oder gcn HD7000 bis rx vega ~70% shader Auslastung Treiber bedingt
nvidia ist das je nach gen wie deren sm Struktur ist
Erste gen geforce 8800 hatte ein sm 8 fp32 shader und 2 sfu die 4 fp32 rechnen konnten Formel 3*sm count*takt*shader pro sm maximal waren das etwa 576gflops 2006
ab tesla 2 gtx200 wo die sfu verringert wurde wurde die formel sm count *Takt *2*alu per sm+ 2*sm count* 4 = der maximale chip erreichte da 1030 gflops das war 2008
fermi gtx400 formel fasst identisch sm count mal alu pro sm*Takt*2 + sm count*4sfu*4 oprationen *takt=1680 gflops
gtx500 serie addierte Nochmal auf 2,0tf das war 2010
gtx600 Serie kam nur ein Mittelklasse chip
gtx700 Serie erst den high end und hievte das limit auf reale sm count *alu pro sm *takt*2+ 32 sfu*4*sm count=6,0tf 2013
gtx900 serie änderte sich die formel nochmal
Da aber kein whitepaper mehr auffindbar ist nehme ich die 4 sfu pro sm noch an das maxed war aber ne titan x mit 7,2tf das war 2015 Ein Jahr später als die gtx980ti kam diese ist Geringfügig langsamer
pascal (gtx10) änderte sich zum ersten mal das die sfu kein fp32 mehr rechnen sm count* 2* alu pro sm*takt= maxed sku hatte 14,5tf 2016
Turing (rtx20)war anders und man setzte zum ersten mal den sm anders auf
Der clou war das man die int32 die immer da waren fp32 rechnen ließ das bedingt zwingend im treiber zu forcieren was ganz klar nicht getan wurde. (bedingt zwingend dx12 oder vulkan)
Formel deswegen sm count * alu pro sm *2*Takt= maxed sku erreichte 17,5tf. 2018
ampere (rtx30) fügte die fp64 Einheiten dazu die fp32 berechnen können
Wenn man so sehen will hat man die int32 fp32 switch Funktion in hardware umgesetzt
Formel für den high end chip aktuell ist sm count* alu pro sm *Takt *2 +fp64 Einheiten pro sm *sm count *Takt *2= 28,8tf 2020
ada derzeit prognostizierte Leistung wäre sm count *2*Takt*alu pro sm mit fp64 66 =42,5tf beim high end chip
Der voll Ausbau ist unklar ob der am desktop kommt.
was nvidia geritten hat die fp64 so drastisch zu senken weis man nicht es sind nur noch 2 fp64 pro sm übrig ampere hatte 24
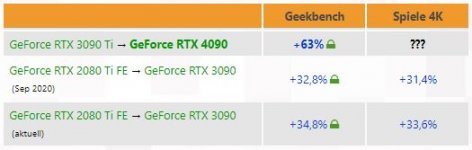
Stellt sich die frage kann man den die 42tf auslasten mit aktuellen cpu?
amd zen4 ryzen 7000 ist kaum schneller als intels ci9 12th gen +10%
Und die cpu sind schon mit der rtx3090ti auf 1440p am kämpfen
Kurz die rtx4090 ist definitiv für 2160p gedacht
Aber ja sofern man die Architekturen richtig auswertet sind diese mit echten tf vergleichen durchaus an Leistung zu vergleichen.
Das problem ist das cpu limit. und das jede Konsolen gen die Anforderungen ansteigen lässt was bestimmte gen an der Speicherbandbreite verhungern.
man kann schlecht ne spiel von 2022 mit ner gpu von 2006 heranziehen ebenso ein spiel von 2006 mit ner gpu von 2022.
Konsolen releases
xbox360 2005 23gb/s 240gflops 720p ziel, erreicht oft 600p
ps4 2013 192gb/s ~1,9tf 1080p ziel, erreicht oft 900p
ps4 pro 2016 256gb/s 4,0tf 1440p ziel, erreicht 1080p
ps5 2020 448gb/s ~10tf 2160p ziel, erreicht 1440p
entsprechend sind die spiele an diesen zu richten
Am pc können die werte extrem höher liegen oder darunter thema cpu limit.
achja fps sind ohne cpu limit linear sofern nicht Speicherbandbreite oder pcie bus limitiert.
und ja cpu limit sind zu 90% Datentransfer von gpu zum ram geschuldet.
Seltener das die cpu nicht schnell genug daten bereitstellen kann.
Das auch der Grund warum Rbar so viel bringt bei cpu limitierten spielen.
Das aber ist primär Treiber bedingt bspw bei nvidia profitiert man kaum von rbar.
Das liegt auch an der Grundlage das nvidia ein task sheduler für den im directx Funktion command list bereitstellt.
Einerseits steigert dies das cpu limit (mehr last auf der cpu) aber insgesamt reduziert es diesen. je mehr kerne daran werkeln.
amd hat das nicht, darum die starke schwäche bei legacy spielen unterhalb von dx11 und bei dx11 muss der Entwickler die command list beachtet haben was auch die schwäche bei amd erklärt in vielen dx11 spielen. (siehe unreal engine spiele)
ja cpu limit isn problem.