Ich hab es schonmal woanders gesagt, ich glaube ich fände es richtig gut, einen SoC mit 2 E Cores oder ZenXc Cores zu bauen, wo im Teillastbereich einfach nur das SoC läuft!
Siehe Meteor Lake, da ist das so vorgesehen im Zentralen SoC.
Es kann der Prozess sein, aber oftmals ist es viel interessanter wie die Architektur ausgelegt ist, Netburst bspw. war damals auf Takt ausgelegt und konnte in jedem Prozess sehr hoch takten. (Die Probleme fingen ja erst bei über 3Ghz an, was damals aber schon enorm war, AMD ist mit 2,2Ghz rumgedümpelt).
ja das stimmt. Ich erinnere mich auch, dass Intel verzweifelt die Taktrate hochgetrieben hat bei gleichzeitig teilweise sinkender IPC weil man die Pipeline verlängern musste
Kann also durchaus sein, dass Arrow Lake einfach nicht für hohe Taktraten ausgelegt ist, dann kannst du da Energie reinpumpen wie du willst, die Grenze wird einfach weit unten sein.
die Architektur von Arrow Lake ist aber dieselbe wie schon die Gens davor. Es hängt hier tatsächlich am Prozess und der Umsetzung.
Andersherum hat Intel ja mit dem 10nm Fiasko bewiesen, dass es eben auch der Prozess sein kann, denn in 14nm++++++++ gingen die Chips ja ganz gut.
Man hat schon vor einigen Jahren gesagt (damals hießen die Prozesse in der Roadmap noch 10nm, 7nm 5nm und es gab dann jeweils ein + und ein ++ davon), dass die erste Gen des neuen Prozesses immer langsamer (Schaltzeiten) sein wird, als die vorige. Die letzten 14nm Prozessoren waren halt deshalb so gut, weil Arhcitektur und PRozess schon sehr gut aufeinander abgestimmt waren.
Ähnliches gibts ja auch im GPU Sektor, die ersten GPUs in einem neuen Prozess werden oft als "pipe cleaner" bezeichnet, erst die GPUs die den Prozess richtig ausnutzen (weil die Entwickler ihn nun kennen) werden oft richtig gut.
Kepler vs Maxwell etwa, beide 28nm
Was mich so ein wenig wundert, hier wird an vielen Stellen so getan als wenn +5% SC und +15% MC ein Erfolg wäre. Sehe ich das so verkehrt, dass dies nach dem 10nm Fiasko der größte Intel Rückschlag seit langem ist? Wir reden hier von fast 2 vollen Nodes Unterschied und Intel kann eine Leistungssteigerung bieten (ja klar, Gerücht) die man mit einem Refresh (also maximal ein besseres Stepping) hinbekommt und das soll auch nur im Ansatz gut sein?
ich sehe nicht, dass irgendjemand das als besonders gut verkauft. Es ist halt der erwartbare Rahmen bei kleinen Optimierungen, mehr Cache und neuer Prozess. +20% wären interessant, aber 5% ist "normal"
Hier aber nochmal: was erwarten die Leute, es ist quasi derselbe Chip in neuer Fertigung. Der Vorteil wird nicht mehr Leistung sein, sondern mehr Effizienz.
Sorry, aber am Ende ist alles unter 50% Mehrleistung im MC für eine Firma wie Intel extrem erschreckend schwach. Wir reden zwar vom Desktop, aber wenn AMD wollen würde, packen die in den Desktop nicht 16 Kerne, nein dann hauen die 32 Kerne auf den Tisch.
Am Ende ist alles unter 30% SC genauso schwach, wir reden von fast 2 Nodes, jeder Node sollte 15% Leistung bringen, also ohne Architekturverbesserung sind 30% ein MUSS!
äh nein, da vermischst du was. Ein Node allein macht ja nix schneller.
Ein neuer Node erlaubt etwa: mehr Transistoren/höhere Transistordichte, mehr Takt oder bei gleichen Werten (Transistormenge, Takt) geringere Leistungsaufnahme.
20A wird der allererste GAA+Backside Power Delivery Prozess sein, er wird wohl eher konservativ ausgelegt und daher wird er eher geringfügige Verbesserungen mit sich bringen.
Ebenso vorsichtig ist man eben auch bei der Architektur: man bringt eben eine gut bekannte (Sunny Cove Weiterentwicklung), statt eine die doppelt so viele Transistoren frisst und voll breit ist.
Das kommt erst bei Intel, man löst sich ja erst von dem Denken, dass für eine Architektur ein ganz bestimmter Prozess vorgesehen ist.
Jetzt muss man erstmal Erfahrung sammeln in 20A/18A um dann zu sehen, ob die wirklich ihre Vorhersagen erfüllen, erst dann kann man beginnen die wesentlich breitere Architektur darin fertig zu designen und zu produzieren.
Bei Grafikkarten ist das ja was ganz anderes: aha es gibt einen neuen Prozess der 40% höhere Dichte erlaubt bei gleichem Verbrauch? Dann verbau ich 40% mehr Hardwareeinheiten (Shader, ROPs usw). Bei CPUs bringt das ja nichts: du kannst in 20A sicher doppelt so viele Transistoren pro Fläche verbauen wie in Intel 7, aber ohne die passende Architektur wären das "nur" mehr Kerne - und davon profitiert außer im Server/Workstationbereich fast niemand.
Sollte inverses Multithreading endlich realität werden, oder andere Spiele-Engines endlich auch den Ansatz von Id Tech 7 verwenden, so könnten wir endlich auch mit mehr Kernen was anfangen.
Ironisch vielleicht: das was wir in Arrow Lake als Architektur der P Kerne bekommen, war schon vor 10 Jahren so geplant (kann man auf altne Folien auch noch so finden):
2016: 10nm Cannon Lake (bekannte Architektur im neuen Prozess)
2017: Ice Lake (Sunny Cove) neue Architektur bzw starke überarbeitung im bekannten Prozess
2018: Tiger Lake: bekannte Architektur im neuen Prozess (7nm, heute "intel 3"
2019: XYZ Lake überarbeitete Architektur in 7nm
2020: XYZ+ Lake in 5nm (heute als 20A/18A bekannt)
Wir kriegen Ende 2024 halt immer noch das, was Intel schon vor 10 Jahren gepant und wenn man so will "in der Schublade" hatte.
Die hat halt geklemmt
")
Allein schon Meteor Lake: die ersten Testchips sind schon seit 2021 fertig, in den Markt kommt er Ende 2023, einfach weil mit dem Prozess teilweise viel neues probiert, aber auch weil man viel vorsichtiger geworden ist.
Klar, nicht immer wird alles perfekt laufen, aber wir reden dann jetzt über die 7. Generation in der von "nicht alles perfekt" bis zu "funktioniert gar nicht" alles dabei war. Dagegen schaut es bei AMD irgendwie so aus, als wenn jede Generation den logischen Schritt geht, mal werden die Kerne erhöht, dann die IPC, dann der Takt und die Efiizienz. Zen5 werden auch schon wieder 15 bis 30% mehr IPC zugeschrieben, selbst wenn wie befürchtet der Takt darunter leiden muss, wird man auch da an der Effizienz drehen und eben wieder einen logischen Schritt gehen, ohne das alles perfekt läuft, aber irgendwie sieht das alles nach einem Plan aus, während Intel planlos hinterherläuft.
Intel und AMD verfolgen hier einen ganz anderen Ansatz, wobei Intel nach und nach mehr in AMDs Richtung schwänkt.
Bei Intel ist bei der Planung einer Architektur früher klar gewesen: es wird ein ganz bestimmter Prozess und dessen Parameter sind auch bekannt. Alles wird perfekt aufeinander abgestimmt. Die Architektur auf den Prozess, gewisse Parameter am Prozess an die Architektur angepasst, auch die Software etc. Das ganze wird still vor sich hin entwickelt bis beides gemeinsam "reif" ist.
Dabei ist halt zu verstehen, dass Intel die Prozesse auf der einen Seite entwickelt und die Architekturen von ganz anderen Leuten. Das läuft parallel, aber dennoch ist es sehr verzahnt. - zumindest war das bislang lange so. Jetzt ist man viel flexibler.
Wenngleich nicht so wie AMD, schließlich muss Intel schon lange vorher planen den Prozess/die Fabs voll auszunutzen sonst wird das unwirtschaftlich.
Bei AMD ist das anders, weil sie keine eigenen Fabs mehr haben:
Sehr vereinfacht: man entwickelt in einem gewissen Rhytmus eine Architektur und wenn sich diese Entwicklung dem Ende nähert schaut man bei TSMC und Co was die so anbieten an Fertigungs und Packagingverfahren. Und dann plant man im jeweils aktuellsten Prozess, danach folgen wirtschaftliche Gedanken wie: wie groß wird der Chip im Verfahren, wieviele Wafer bestellt man, welche Yields, was kostet uns das, wie müssen wir die Produkte positionieren usw usf.
Es ist quasi - auch wieder völlig vereinfacht - ein wenig "von der Stange". Man geht mit einer Architektur durch und "bedient" sich an den parallel bei TSMC und Co entwickelten Prozessen.
Ein ähnliches Verfahren ja auch AMD intern: man arbeitet ja an verschiedenen Dingen und das jeweils zuletzt fertig gestellte stöpselt man zu einer neuen CPU/APU zusammen, in einer Konfiguration wie sie der Kunde wünscht.


.gif "sm_B-) :-)") (Die ich mir leider nicht gespeichert habe.
(Die ich mir leider nicht gespeichert habe.  )
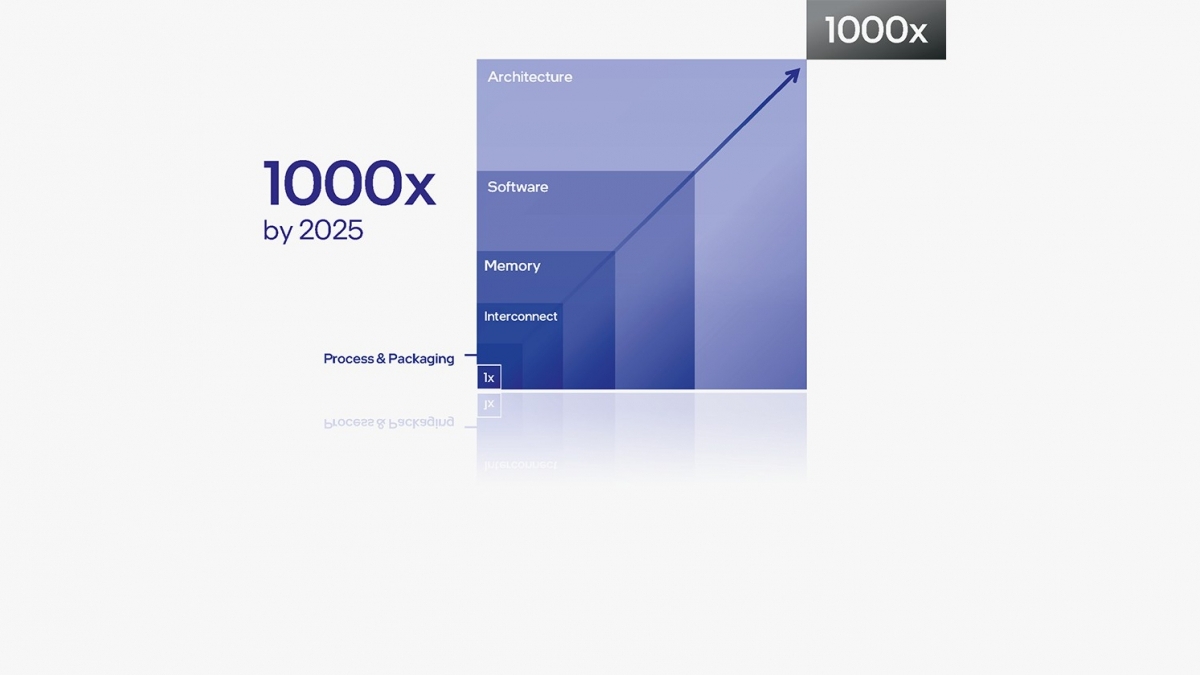
)
") Selbst die ältesten Tiger-Lake-Gerüchte in Textform sind schon PAO, dementsprechend auch 10 nm und nicht Tick Tock, offizielle Folien folgten lange später. Das älteste, was ich finden konnte, was eine 2016er Gerüchte-Auswertung von guru3d. Damals wusste man noch nichts von Sunny Cove, sortierte Tiger Lake relativ zu Ice Lake aber bereits wie Kaby Lake zu Skylake ein, also als Willow-Cove-Rebrand ganz ohne Neuerungen.
Selbst die ältesten Tiger-Lake-Gerüchte in Textform sind schon PAO, dementsprechend auch 10 nm und nicht Tick Tock, offizielle Folien folgten lange später. Das älteste, was ich finden konnte, was eine 2016er Gerüchte-Auswertung von guru3d. Damals wusste man noch nichts von Sunny Cove, sortierte Tiger Lake relativ zu Ice Lake aber bereits wie Kaby Lake zu Skylake ein, also als Willow-Cove-Rebrand ganz ohne Neuerungen.