Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
AMD RX VEGA Laberthread
- Ersteller Ralle@
- Erstellt am
Locuza
Lötkolbengott/-göttin
Es ist eine allgemeine Beschreibung, wie der Vorgang funktioniert.Ah ok, ich hatte das schon so verstanden, dass in dem Schritt das Primitives-Verwerfen passiert, aber danke für die Klarstellung. Allerdings steht ja drinnen, dass der sich Primitives sucht. (...The DSBR works by first dividing the image to be rendered into a grid of bins or tiles in screen space and then collecting a batch of primitives...The DSBR then traverses the batched primitives one bin at a time, determining which ones are fully or partially covered by the bin)
Dementsprechend hatte ich das mit dem Culling schon so verstanden und bin auch davon ausgegangen, dass das in dem Schritt mitläuft. (Lass mich aber natürlich gerne belehren). Primitive Culling ist ja eigentlich auch der Schritt der nach dem Primitive Shader passieren würde. Wobei ich dachte, dass das immernoch zur NGG gehört. Oder ist der DSBR dann erst in nem Schritt danach (also nach dem Primitive Binning) oder etwa schon davor?
Der Primitive Shader kann doch nur die Reihenfolge asynchron machen so wie ich das verstanden hab? Also so dass die verschiedenen Unterschritte teils out of order passieren können indem er Aufrufe zusammenfasst?
Viele Fragen, ich weiß aber ich dachte eigentlich das ich das konzeptionell richtig aufgenommen hatte...^^
Hab hier mal 2 Teile aus 2 Diagrammen aus dem Vega Paper:

Links ist aus dem NGG Teil aus dem Dokument mit in sich links der klassischen Geometrieverarbeitung und rechts der neuen mit Primitive Shaders und rechts einem Auszug aus dem Architekturdiagramm. Ich hatte die Unterteilung immer so verstanden. Gehört der Tesselator dann auch in die Geometry-Engine?
Der DSBR arbeitet pro Kachel und in jedem Kachel findet sich ein Haufen Primitives, wo diese dann gerastert werden.
Hierbei kann der DSBR auch dynamisch arbeiten, nämlich wie groß die Kacheln ausfallen und entsprechend wie viel Geometrie sich darin befindet, dabei muss man auch feststellen, welche Primitives oder sagen wir einfach Dreiecke sich in einer Kachel ganz oder nur teilweise befinden.
Primitive Binning bezeichnet dabei die Zusammenstellung von Primitives für eine Kachel, nicht das Verwerfen von Geometrie.
Gerastert werden fertige Geometriedaten, wo die Geometriepipeline mit der Verarbeitung und Culling fertig ist.
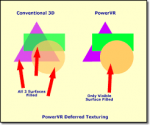
Beispielhaft ein Schaubild von Imagination:
A look at the PowerVR graphics architecture: Tile-based rendering - Imagination
Bezogen auf NGG und Primitive Shader habe ich eine ausführlichere Interpretation von mir im 3DCenter geschrieben, wie gesagt das ist mein Denkbild, wie es aktuell aussieht:
3DCenter Forum - AMD/ATI - VEGA (Vega10, Vega11, Vega12, Vega20) - 2017 - Seite 703
Das Schaubild daraus nehme ich mal trotzdem dazu für eine Kurzfassung:
Oben in grün ist die aktuell klassische Pipeline dargestellt, unten in Orange NGG, was nicht (vollständig) aktiv ist.
Klassisch betrachtet arbeitet zuerst die World-Space-Pipeline die Geometrie ab.
Die CPU liefert die Geometrie-Daten, dann nimmt die GPU das auf, der Input-Assembler gibt es an die Shader weiter, dann läuft entsprechend irgendein Shader-Typ ab und davor und danach sind auch die Geometrie-Engines für unterschiedliche Berechnungen zuständig.
Auch das Culling über die im Patent genannten Primitive Assembler.
Der Output wird in dedizierten Position/Parameter-Caches gespeichert und dann läuft der Rastervorgang durch Fixed-Function-Rasterizer ab, dann gehen die Pixel-Shader drüber und zum Schluß spucken die Fixed-Function ROPs die finalen Werte für das Bild heraus.
Bezogen auf die Geometrieverarbeitung hat die klassische Pipeline ein paar Probleme.
1. Die Skalierung, man benötigt für eine direkte Anbindung von Shader-Engine zu Shader-Engines (Shader-Engine = Geometry-Engine + Rasterizer) eine Crossbar und wenn man den Geometriedurchsatz durch weitere Engines erhöhen möchte, explodiert der Aufwand bei der Verdrahtung.
2. Die dedizierten Caches für die Daten sind relativ speziell und können nur von der Grafik-Pipeline ausgenutzt werden, für Compute-Shader sind die Buffer völlig nutzlos oder für allemeines programmieren.
Auch ist deren Größe ein Problem, ist ein Buffer voll und gibt es Abhängigkeiten beim Raster-Vorgang, dann muss jede Shader-Engine auf die eine Engine warten, die gerade überfüllt ist und wenn man die Caches dann größer macht, ja dann verschwendet man natürlich mehr Chipfläche für diesen speziellen Vorgang.
3. Primitive Culling erfolgt nach der World-Space-Verarbeitung bzw. wenn Vertex/Geometry-Shader darüber laufen, dass siehst du auch im Schaubild vom Whitepaper.
Das heißt du kannst umsonst Vertex/Geometry-Shader berechnet haben, für Geometrie die erst danach verworfen wird.
NGG/Primitive Shader würden das Ganze anders umsetzen.
1. Die bestehende Infrastruktur bei den Shadern würde man ausnutzen und es wäre nicht nötig diese dedizierte Crossbar bei den Shader-Engines zu haben bzw. wäre nicht zwingend gezwungen das weiter zu skalieren.
2. Die Daten bei der Verarbeitung würde man im LDS (64KB Local Data Share, allgemeine Ressource pro Compute Unit) speichern und die Rasterizer darauf zugreifen.
3. Primitive Shader könnten das Culling bewerkstelligen bevor effektiv Vertex-Shading und ähnliches abläuft bzw. man unnötige Attribute ausrechnet.
Im Whitepaper siehst du zwei mal Primitive Culling, einmal rechts beim Primitive Shader und einmal unten beim Primitive Assembler.
Culling danach über Primitive Assembler könnte man durch Primitive Shader sich dann ganz sparen, wobei es auch denkbar wäre Beides zu verwenden, Primitive Shader die eine Art von Culling durchführen und Primitive Assembler die danach noch weiter Geometrie verwerfen.
Und ja, der Tessellator findet sich in den Geometry-Engines (Geometry/Vertex-Assembler = Primitive Assembler):
Anhänge



")
Locuza
Lötkolbengott/-göttin
Das liest sich genauso so.Das liest sich im White paper aber anders
Man spart ja gerade Bandbreite weil nicht jedes Polygon im Rasterizer verwendet wird.
Der DSBR-Vorgang beschreibt Pixel-Culling, nicht Geometry-Culling.
Wenn Teile von der Geometrie sich überlappen, dann muss man nicht das Pixel-Shading für Farbwerte ausführen, die im Hintergrund sind.
Hier geht es nicht dabei um festzustellen, welche Geometrie die andere überlappt und welche Teile der Geometrie man dann verwerfen kann, sondern welche Geometrie sich überlappt, wo man sich die Berechnung der Farbwerte sparen kann, die verdeckt sind.
Locuza
Lötkolbengott/-göttin
Klassisch gesehen wird bei einem IMR so nicht gearbeitet, es wird jedes Dreieck einzeln gerastert und die Farbwerte ausgerechnet, dabei kann es dann in der finalen Szene vorkommen, dass Objekte in der Szene andere Objekte verdecken, wofür man dann umsonst die Farbwerte ausgerechnet hat, dass wird auch als Overdraw bezeichnet.
Der DSBR sammelt dagegen Geometrie in einer Kachel, führt einen Tiefentest durch und rastert dann nur die Farbwerte, die final sichtbar sind.
In der Folie steht selber "shade once enabled by culling of pixels invincible to the scene", da steht nichts von primitive culling.
Der DSBR sammelt dagegen Geometrie in einer Kachel, führt einen Tiefentest durch und rastert dann nur die Farbwerte, die final sichtbar sind.
In der Folie steht selber "shade once enabled by culling of pixels invincible to the scene", da steht nichts von primitive culling.
Anhänge
drstoecker
Lötkolbengott/-göttin
Ich versteh nur Bahnhof Jungs!
Ich versteh nur Bahnhof Jungs!
Geht mir auch so. Leider keine Zeit bisher ums richtig zu lesen aber bein überfliegen klingts schon sehr interessant und informativ, also wegen mir macht ruhig weiter

EyRaptor
BIOS-Overclocker(in)
Ich versteh nur Bahnhof Jungs!
Mir geht es gerade auch ein wenig so
, aber es ist dennoch ein spannendes Thema.Primär gehts mir um den realen Stromverbrauch. Benchmarks kann ich genug lesen. Wenn du ein Strommeßgerät hast oder schonmal getestet hast, wüßte ich z. B. gerne wieviel dein Sys 2 an Watt aus der Steckdose nimmt beim Gaming. Dann hätte ich schonmal einen ungefähren Anhaltspunkt. Die Testseiten benutzen meistens 6 Core Systeme übertaktet und was die an Strom weghauen, da komm ich bei weitem nicht hin.
Jetzt kann ich theoretisch mit den Messungen anfangen.
Bisher funktioniert dieser quick&dirty Test-Aufbau allerdings noch nicht und das Board spuckt mir dauernd GPU errors aus.
Das Troubleshooting spare ich mir aber wohl für Morgen auf.
Sobald ich verwertbare Ergebnisse habe, werde ich die in diesem Thread -> RX 4X0 / Vega - Laberthread posten,
da es hier primär um Vega geht und es damit offopic wäre.
Anhänge


Tja mit dem Frontend Sollte man sich schon mal Befassen und die Richtige Fragen stellen.
Früher gab es Tests die waren schön aufgeschlüsselt. Da wurden reine Polygonentests reine Tesslationtests, Texturetests und Shadertests gemacht. Das macht leider kein Magazin mehr...
Früher gab es Tests die waren schön aufgeschlüsselt. Da wurden reine Polygonentests reine Tesslationtests, Texturetests und Shadertests gemacht. Das macht leider kein Magazin mehr...
Ace
BIOS-Overclocker(in)
Vielleicht hat ja einer Interesse,hab ich gerade gesehen in Ebay.
Radeon RX Vega 64 mit Eiswolf GPX-Pro
Radeon RX Vega 64 mit Eiswolf GPX-Pro
Wenn Ihr mehr über das Frontend wissen wollt. Ich hab hierzu mal einen Test angefragt. Mit jedem Like wächst die Chance das wir das sehen. Bitte liken oder noch besser das kommentieren dann kommt auch etwas dazu:
http://extreme.pcgameshardware.de/p...ie-naechste-pcgh-ausgabe-417.html#post9597046
http://extreme.pcgameshardware.de/p...ie-naechste-pcgh-ausgabe-417.html#post9597046
Locuza
Lötkolbengott/-göttin
Noch bis zu Vega wurde das relativ fleißig von hardware.fr, PCGH und Techreport gemacht.Tja mit dem Frontend Sollte man sich schon mal Befassen und die Richtige Fragen stellen.
Früher gab es Tests die waren schön aufgeschlüsselt. Da wurden reine Polygonentests reine Tesslationtests, Texturetests und Shadertests gemacht. Das macht leider kein Magazin mehr...
Aber ein wichtiger Redakteur bei hardware.fr ist zu AMD gewechselt und die Seite macht nichts mehr, bei The Techreport ist auch ein Redakteur zu AMD gegangen, die machen jetzt nicht mehr die Theorietests und bei PCGH ist Carsten zu Heise gegangen und bei Turing gab es dann keine Betrachtungen mit der Beyond3D Suite mehr.
Vega-Test:
http://www.pcgameshardware.de/Radeo...6623/Tests/Benchmark-Preis-Release-1235445/3/
Computerbase und PCGH testen auch mal Tessellation-Samples oder Spiele damit und stellen die Leistung in Relation dar, dass gibt einem auch immerhin einen Einblick.
Man kann sich natürlich immer mehr wünschen.
Z.B. Theorietest die kostenlos sind und jedem offen stehen, Theorietests die gut programmiert sind und auch wirklich viele relevanten Daten liefern und nicht nur relativ simple Szenen darstellen, mit relativ wertlosen Messergebnissen.
Praktische Betrachtungen unter unterschiedlichen Spielen, denn Praxisergebnisse interessieren den Konsumenten am meisten und jedes Spiel ist unterschiedlich.
Ja jedes Spiel ist unterschiedlich. Darum geht es mir ja gerade und da auch jede Architektur unterschiedlich ist kann beim einen das erhöhen oder veringeren einer Einstellung erhebliche Auswirkungen haben oder eher nicht. Deshalb sind einzeltest immer besser als wenn man alles auf Ultra testet.
J
Johnjoggo32
Guest
Es ist eine allgemeine Beschreibung, wie der Vorgang funktioniert.
Der DSBR arbeitet pro Kachel und in jedem Kachel findet sich ein Haufen Primitives, wo diese dann gerastert werden.
Hierbei kann der DSBR auch dynamisch arbeiten, nämlich wie groß die Kacheln ausfallen und entsprechend wie viel Geometrie sich darin befindet, dabei muss man auch feststellen, welche Primitives oder sagen wir einfach Dreiecke sich in einer Kachel ganz oder nur teilweise befinden.
Primitive Binning bezeichnet dabei die Zusammenstellung von Primitives für eine Kachel, nicht das Verwerfen von Geometrie.
Gerastert werden fertige Geometriedaten, wo die Geometriepipeline mit der Verarbeitung und Culling fertig ist.
Beispielhaft ein Schaubild von Imagination:
A look at the PowerVR graphics architecture: Tile-based rendering - Imagination
Bezogen auf NGG und Primitive Shader habe ich eine ausführlichere Interpretation von mir im 3DCenter geschrieben, wie gesagt das ist mein Denkbild, wie es aktuell aussieht:
3DCenter Forum - AMD/ATI - VEGA (Vega10, Vega11, Vega12, Vega20) - 2017 - Seite 703
Das Schaubild daraus nehme ich mal trotzdem dazu für eine Kurzfassung:
Oben in grün ist die aktuell klassische Pipeline dargestellt, unten in Orange NGG, was nicht (vollständig) aktiv ist.
Klassisch betrachtet arbeitet zuerst die World-Space-Pipeline die Geometrie ab.
Die CPU liefert die Geometrie-Daten, dann nimmt die GPU das auf, der Input-Assembler gibt es an die Shader weiter, dann läuft entsprechend irgendein Shader-Typ ab und davor und danach sind auch die Geometrie-Engines für unterschiedliche Berechnungen zuständig.
Auch das Culling über die im Patent genannten Primitive Assembler.
Der Output wird in dedizierten Position/Parameter-Caches gespeichert und dann läuft der Rastervorgang durch Fixed-Function-Rasterizer ab, dann gehen die Pixel-Shader drüber und zum Schluß spucken die Fixed-Function ROPs die finalen Werte für das Bild heraus.
Bezogen auf die Geometrieverarbeitung hat die klassische Pipeline ein paar Probleme.
1. Die Skalierung, man benötigt für eine direkte Anbindung von Shader-Engine zu Shader-Engines (Shader-Engine = Geometry-Engine + Rasterizer) eine Crossbar und wenn man den Geometriedurchsatz durch weitere Engines erhöhen möchte, explodiert der Aufwand bei der Verdrahtung.
2. Die dedizierten Caches für die Daten sind relativ speziell und können nur von der Grafik-Pipeline ausgenutzt werden, für Compute-Shader sind die Buffer völlig nutzlos oder für allemeines programmieren.
Auch ist deren Größe ein Problem, ist ein Buffer voll und gibt es Abhängigkeiten beim Raster-Vorgang, dann muss jede Shader-Engine auf die eine Engine warten, die gerade überfüllt ist und wenn man die Caches dann größer macht, ja dann verschwendet man natürlich mehr Chipfläche für diesen speziellen Vorgang.
3. Primitive Culling erfolgt nach der World-Space-Verarbeitung bzw. wenn Vertex/Geometry-Shader darüber laufen, dass siehst du auch im Schaubild vom Whitepaper.
Das heißt du kannst umsonst Vertex/Geometry-Shader berechnet haben, für Geometrie die erst danach verworfen wird.
NGG/Primitive Shader würden das Ganze anders umsetzen.
1. Die bestehende Infrastruktur bei den Shadern würde man ausnutzen und es wäre nicht nötig diese dedizierte Crossbar bei den Shader-Engines zu haben bzw. wäre nicht zwingend gezwungen das weiter zu skalieren.
2. Die Daten bei der Verarbeitung würde man im LDS (64KB Local Data Share, allgemeine Ressource pro Compute Unit) speichern und die Rasterizer darauf zugreifen.
3. Primitive Shader könnten das Culling bewerkstelligen bevor effektiv Vertex-Shading und ähnliches abläuft bzw. man unnötige Attribute ausrechnet.
Im Whitepaper siehst du zwei mal Primitive Culling, einmal rechts beim Primitive Shader und einmal unten beim Primitive Assembler.
Culling danach über Primitive Assembler könnte man durch Primitive Shader sich dann ganz sparen, wobei es auch denkbar wäre Beides zu verwenden, Primitive Shader die eine Art von Culling durchführen und Primitive Assembler die danach noch weiter Geometrie verwerfen.
Und ja, der Tessellator findet sich in den Geometry-Engines (Geometry/Vertex-Assembler = Primitive Assembler):
Ok, ist sehr interessant. Danke für's Richtigstellen.
Gurdi
Community-Legende
Ist ja mal ganz praktisch das die Bilder hier so zu sehen sind.
Die GCN Gen 5 Pipeline von Locuza.
Anhang anzeigen 1019815
Die kann man komplett verwerfen so. Das System wurde völlig neu aufgezogen und hat wenig mit dem alten Ansatz zu tun, er hat wohl schlicht nicht funktioniert.
Das Ganze sieht jetzt so aus:

Das sieht dann so aus im Detail.
Beschreibung der Skizze
Das ganze läuft unabhängig von einer Unterstützung von Entwicklern, läuft aber besser mit.
Der Hauptvorteil:
und vor allen Dingen
Das alles passiert bevor es in den Ringbus, Cache oder sonst wo landet.
Der Vertex Shader wird völlig anders verwendet in dem Zusammenhang.
1. Die Crossbar fällt weg, der Scheduler verteilt nur noch. Die Aufteilung für die Renderpipeline erfolgt bereits vorher.
2. Die werden geschrieben und es wir darauf zugeriffen, wenn dies nicht passiert werden die Daten vorgehalten falls ein weiterer Zugriff diese verwenden kann. Wenn die Daten nirgend gebraucht werden, dann werden diese verworfen ohne das diese die Renderpipeline belastet haben.
3. Das ist mit der neuen Methode ebenfalls der Fall, wenn auch abgewandelt da die Vertex Shader zumindest für das Fetch Shader Modul vorarbeiten.
Die GCN Gen 5 Pipeline von Locuza.
Anhang anzeigen 1019815
Die kann man komplett verwerfen so. Das System wurde völlig neu aufgezogen und hat wenig mit dem alten Ansatz zu tun, er hat wohl schlicht nicht funktioniert.
Das Ganze sieht jetzt so aus:

Die Pipeline 134 kriegt also quasi alles im VORFELD des Rendering Prozesses vorgekaut.A pre-processing compute shader stage 330 is coupled to the graphics processing pipeline 134. The pre-processing compute shader stage 330 allows computational work to be performed on primitives received from outside of the APD 116 (e.g., from the processor 102) before being processed by the graphics processing pipeline 134. The pre-processing compute shader stage 330 executes pre-processing compute shader programs received from, for example, the processor 102. These pre-processing compute shader programs accept specified inputs, such as primitives or vertices, and produce specified outputs, such as modified primitives or vertices.
Das sieht dann so aus im Detail.

WeiterführendOne use for the pre-processing compute shader stage 330 is to perform culling.
[0037] In another technique, the pre-processing compute shader stage 330 performs at least some culling operations that would otherwise be performed by the graphics processing pipeline 134. The benefit of such a technique is that the number of primitives that travel through and are processed by the graphics processing pipeline 134 is reduced. However, one difficulty with this technique is that operations for calculating the vertex transforms to determine transformed vertex positions necessary for performing the culling operations are not performed until the vertex shader stage 304.
[0038] To alleviate this difficulty, the driver 122, which generates compiled shader programs (such as vertex shader programs) from shader programs received from other software being executed by the processor 102, is configured to automatically generate shader programs for culling based on the vertex shader programs received from the other software. In one example, an application 126 provides vertex shader programs that include instructions for, among other things, transforming the position of vertices received by the vertex shader stage 304 of the graphics processing pipeline 134. Such vertex shader programs also define instructions for performing operations to modify or generate non-position attributes for vertices, such as values that define vertex lighting, color, texture coordinates, or any other aspect of vertices that do not define position of the vertices within rendering space.
Beschreibung der Skizze
Figure 4 is a block diagram that illustrates automatically generated compute shaders for pre-graphics-pipeline culling. The driver 122 generates a cull shader program 410 and a transform shader program 430, and, optionally, a fetch shader program 420, based on a vertex shader program 402 that is provided to the driver 122 for execution at the vertex shader stage 304.
Das ganze läuft unabhängig von einer Unterstützung von Entwicklern, läuft aber besser mit.
Basing the transform shader program on the vertex shader program allows culling to be done based on customized vertex position transforms that can be defined by a programmer. Further, because the cull shader program and transform shader program are automatically generated,
a programmer does not need to explicitly invoke primitive culling operations, which simplifies the application development process and reduces cost and time for development of software that utilizes the graphics processing pipeline.
Der Hauptvorteil:
One advantage of the generated shader programs is that each such shader program can process multiple vertices at the same time. When executed on a highly parallel architecture such as the one described with respect to Figure 2, each instance (e.g., each work-item) of the shader program can process multiple vertices.
und vor allen Dingen
The vertex shader program would still compute transforms for non-position attributes. The driver 122 could use dead code elimination to remove instructions that only contribute to position transforms and could also modify the vertex shader programs to simply pass through the already transformed vertex positions, accepting such transformed positions as input and transmitting the transformed vertex positions out as output.

Das alles passiert bevor es in den Ringbus, Cache oder sonst wo landet.
Der Vertex Shader wird völlig anders verwendet in dem Zusammenhang.
A software module, such as a just-in-time compiler component of a driver being executed by a host CPU, automatically generates the shader programs based on a vertex shader program that is provided for use in the vertex shader stage of the graphics processing pipeline. As is generally known, the vertex shader stage of the graphics processing pipehne may involve execution of a vertex shader program to transform vertex coordinates and to modify or generate other attributes of the vertices as needed. Vertex shader programs are often embedded within application programs for transmittal to and execution by the graphics processing pipeline, to process primitives received from the host CPU. The automatically generated shader programs include instructions from the vertex shader program that transform the positions of vertices provided as input to the graphics processing pipeline to generate transformed input vertices. The shader programs also include instructions to cull primitives based on the transformed input vertices. The shader programs do not, however, include instructions for transforming or generating non-position attributes of input vertices, because the output of these instructions are not used by the culling instructions.
Note that the actual vertex shader program 402 that is executed at the vertex shader stage 304 is not deleted or replaced but is still executed at that stage. In some alternatives, the vertex shader program 402 is modified to
receive inputs from the outputs of the automatically generated shader programs, and/or in line with other modifications described herein such as to use transformed vertex positions generated by the automatically generated shader programs. Note also that the call instructions described above (e.g., call fetch shader instruction 414, call transform shader instruction 426, and return to cull shader instruction 438) may be implemented simply with instructions that directly set the program counter, to avoid the overhead associated with function calls or the like.
NGG/Primitive Shader würden das Ganze anders umsetzen.
1. Die bestehende Infrastruktur bei den Shadern würde man ausnutzen und es wäre nicht nötig diese dedizierte Crossbar bei den Shader-Engines zu haben bzw. wäre nicht zwingend gezwungen das weiter zu skalieren.
2. Die Daten bei der Verarbeitung würde man im LDS (64KB Local Data Share, allgemeine Ressource pro Compute Unit) speichern und die Rasterizer darauf zugreifen.
3. Primitive Shader könnten das Culling bewerkstelligen bevor effektiv Vertex-Shading und ähnliches abläuft bzw. man unnötige Attribute ausrechnet.
1. Die Crossbar fällt weg, der Scheduler verteilt nur noch. Die Aufteilung für die Renderpipeline erfolgt bereits vorher.
2. Die werden geschrieben und es wir darauf zugeriffen, wenn dies nicht passiert werden die Daten vorgehalten falls ein weiterer Zugriff diese verwenden kann. Wenn die Daten nirgend gebraucht werden, dann werden diese verworfen ohne das diese die Renderpipeline belastet haben.
3. Das ist mit der neuen Methode ebenfalls der Fall, wenn auch abgewandelt da die Vertex Shader zumindest für das Fetch Shader Modul vorarbeiten.
Zuletzt bearbeitet:
G
Gast1728637801
Guest
Auf den Diagrammen schaut das ja sooo einfach und logisch aus. Bis das aber mal in Software drin ist, haben sich Horden von Programmierern daran ihr Hirn verbogen. 
Bild: rtx3d1frq.png - abload.de
Bild: rtx613c8z.png - abload.de
RTX oder wie immer man es heißen will auf RX Vega (RTX Vega)
Treiber von Shadow of The Tomb Raider ist am Testen, bringt gute 30% an Mehrleistung
dafür aber Stürzt jener Verdammt oft ab, sind am Fixen!
Bild: rtx613c8z.png - abload.de
RTX oder wie immer man es heißen will auf RX Vega (RTX Vega)
Treiber von Shadow of The Tomb Raider ist am Testen, bringt gute 30% an Mehrleistung
dafür aber Stürzt jener Verdammt oft ab, sind am Fixen!
HunterChief
Freizeitschrauber(in)
RTX oder wie immer man es heißen will auf RX Vega (RTX Vega)
Sorry ... aber das sind doch nur normale Spiegelungen von Objekten die auch im Bild zu sehen sind !?!
RtZk
Lötkolbengott/-göttin
Bild: rtx3d1frq.png - abload.de
Bild: rtx613c8z.png - abload.de
RTX oder wie immer man es heißen will auf RX Vega (RTX Vega)
Treiber von Shadow of The Tomb Raider ist am Testen, bringt gute 30% an Mehrleistung
dafür aber Stürzt jener Verdammt oft ab, sind am Fixen!
Das ist kein Raytracing.
Wenn es auf Vegas aktivierbar ist, dann würden ~4 FPS auf dem Zähler stehen.
Ähnliche Themen
- Antworten
- 11
- Aufrufe
- 1K
- Antworten
- 19
- Aufrufe
- 5K
- Antworten
- 8
- Aufrufe
- 2K
- Antworten
- 12
- Aufrufe
- 4K
- Antworten
- 9
- Aufrufe
- 2K