Wie kommst du darauf? Es gibt aktuell kein einziges 16GB Dual Rank Modul.
Ich tippe mal das damit, wie bei Intel, die Dimms per Channel gemeint sind und damit wäre bei Boards mit 4 Slots 4800MT/s der Standard und bei 2 Slots 5600MT/s.
Ich komme da nicht drauf. Es ist ein Gerücht. ^^ Bei Intel sieht es übrigens so aus. Single vs. dual ranked spielt nur eine Rolle, wenn 4 Module verwendet werden.
Alder Lake hat aber relativ schlechte Cache Latenzen. Zudem ist die Geschwindigkeit des L1 und L2 im Vergleich zu den Vorgängern insgesamt niedriger. Grösse alleine sagt nicht viel aus.
Nah, Alder Lake hat rund 15% schlechtere L2 Latenzen im Vergleich zu Rocket Lake. Man muss das in Relation setzen. Durch die schiere Größe wird ein großer Vorteil gewonnen. Die Hitrate steigt dadurch beachtlich an.
Anandtech schreibt dazu:
On the L2 side of things, compared to Rocket Lake’s Willow Cove cores, Alder Lake’s Golden Cove cores considerably increase the L2 cache from 512KB to 1.25MB. This does come at a 15% latency degradation for this cache, however given the 2.5x increase in size and thus higher hit rates, it’s a good compromise to make.
Eher nicht. Es sind ja nur ~4% maximaler Taktunterschied zwischen 3950X und 5950X. Da können keine 6% durch den Takt kommen.
Hast du die CPUs da? Hast du umfangreiche Tests gemacht? Das ist bei mir tatsächlich der Fall, ansonsten würde ich nicht solche Aussagen tätigen. Der 3950X boostet in Spielen auf ca. 4.3GHz allcore, der 5950X liegt fast 500MHz drüber. Rechnen wir mit 4.75GHz im Mittel, dann kommen wir auf ca. 10.5% mehr Takt, welche in ca. 6% mehr Leistungen umgewandelt werden können.
Edit: Hier mal ein Beispiel von meinem Alder Lake Launchreview. Das höchste, was ich an Boosttakt gefunden habe, ist Crysis Remastered. Das sind nicht mal 4.3GHz CPU Max Clock im Mittel.
Und wenn man die 15% vom 5800X3D durch dreifachen L3 mit etwas schlechteren Latenzen und niedrigerer Taktrate betrachtet, dann wären vielleicht 12% durch doppelten L3 realistisch.
Doch, das macht ca. 12%. Hier bei PCGH ist der 5800X3D 22% schneller als ein 5800X. Taktbereinigt sind das locker 25%. Das kommt
ausschließlich vom Cache. Und du zweifelst immer noch daran, dass 12% bei Vermeer durch den Cache kommen? Du machst dabei übrigens einen Denkfehler, siehe folgende Punkte.
Wenn er denn wirklich doppelte Kapazität hätte. So wie bei Vermeer im Vergleich zu Cezanne. Hat er aber nicht. Vermeer und Matisse haben die gleiche L3 Kapazität. Nur hat der L3 Zugriff bei Matisse teils eine höhere Latenz. Das macht aber keine 12% aus.
Es zählt aber nicht die Gesamtkapazität, sondern jene Kapazität auf die ein Thread maximal zugreifen kann, ohne teure Remotezugriffe auf den L3 Cache des anderen CCX's.
Zumal der RAM Zugriff immer noch deutlich langsamer ist. Der L3 Zugriff limitiert auch bei Zen 3 schon vor den 32 MB, z.B. aufgrund des L2 TLB. Anandtech macht da immer recht interessante Analysen. Ich kann nur empfehlen, sich das mal durchzulesen.
Wie kann denn Ryzen 3D taktbereinigt 25% in Games zulegen, wenn der L2 der (dominierend?!) limitierende Faktor ist?
Ich denke ein Grossteil der höheren Gaming Performance ist auf jeden Fall auch auf die Verbesserungen der Architektur zurückzuführen. Hier wurden einige Flaschenhälse angegangen, was gerade auch bei Spielen einiges bringen sollte. Wie Prefetching, Micro-op Cache oder Load/Store.
Nein, du irrst dich. Der Großteil der Gamingperformance bei Vermeer kommt durch Cache und Takt. Außerdem, wie kann der Flaschenhals angegangen werden, indem man die Cores aufbohrt, wo doch der Flachenhals weiter "vorne", nämlich beim Speichersystem (Caches gehören dazu) liegt?
Teile der Leistungsteigerungen kommen natürlich durch die bessere Architektur. Das ist aber weniger als du denkst.
Nee, so einfach ist das nicht. Denn die Verbesserungen an der Architektur für mehr IPC sorgen genau dafür, dass die Daten effizienter und schneller von der Pipeline abgearbeitet werden können. So wie schnellerer Cache und Speicher dafür sorgen, dass die Daten schneller eingelesen werden können. Die Balance ist entscheidend.
Aber die Pipeline (ist übrigens was Logisches, nichts Physikalisches) muss doch schlicht auf Daten warten, wenn das Speichersystem limitiert. Schau dir einfach mal die Hitrates auf die Caches mit einem Profiler an.
Aber ja, die Balance ist tatsächlich entscheidend, denn andererseits bringt es wenig, wenn das Speichersystem blitzschnell ist, aber die Kerne zu schwach sind, die Daten wegzuschaufeln. Genau das ist bei modernen Architekturen aber
nicht Fall. Prefetching kann übrigens keine Wunder bewirken, nur mal so am Rande. Je "randomisierter" auf die Daten zugriffen wird, desto weniger bringt Prefetching.
Sofern man mit mehr Bandbreite höhere Latenzen mindestens kompensieren kann, sehe ich da kein Problem.
Könnte man, aber wie soll das gehen, wenn das Grundprinzip weiterhin ein Interconnect auf einem Substrat ist? Latenzen hängen nun mal stark am Takt. Klar, es gibt immer weitere Möglichkeiten, aber am Ende müssen sie geringere Taktraten überkompensieren. Ich bin wirklich gespannt, wie sie das anstellen wollen.
Z.B. wurde das 5 GHz All Core Sample auf der CES anhand eines Spiels demonstriert. AMD hat auch immer wieder in Interviews betont, dass ein Fokus von Zen 4 Gaming war.
In welchem Interview wurde das gesagt, dass der Fokus Gaming war? Ich denke sogar, dass Zen 4 in Games scheinen kann. Dafür braucht es aber sehr schnellen DDR5 oder eben den Refresh mit stacked L3 Cache.



") Und das obwohl AMD selbst ja von einem üppigen Leistungsplus gesprochen hat...
Und das obwohl AMD selbst ja von einem üppigen Leistungsplus gesprochen hat...


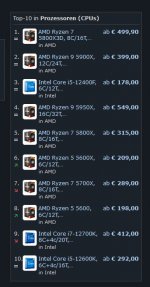





")
