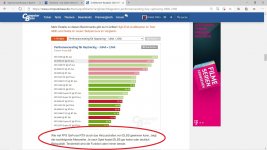
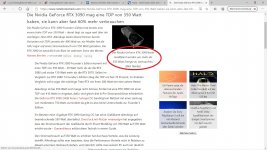
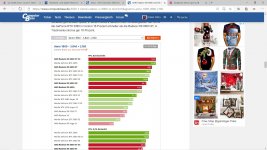
Welche sollen das denn sein?
Fakt ist, dass die Rasterleistung von RDNA2 viel höher ist und Nvidia mit Ampere eine reine compute Architektur für Gamer nur aufgebohrt hat, ergo ein Kompromiss ist.
Während AMD bereits mit RDNA3 auf den MCM Zug aufspringen wird, ist dieser für Nvidia bereits abgefahren.
Nach dem Meme das GCN eine reine Compute Architektur nur mit etwas Grafik sei, finde ich es lustig jetzt einen Beitrag zu lesen, der das jetzt von Bezug auf Nvidia's Ampere Architektur behauptet.

Vega?
@News: freu mich schon, hoffentlich funktioniert das Ding mindestens so gut wie DLSS2.0, wenn dann noch Open Source (und somit auch von Intel genutzt) - perfekt, endlich würden das dann viel mehr Spiele unterstützen
"Overclockers dream" wurde von AMD's Joe Macri beim Fiji event genannt, der minimal übertaktbar war trotz Wasserkühlung (7-8% für ungefähr 4% mehr Mehrleistung):
https://www.computerbase.de/2015-06/amd-radeon-r9-fury-x-test/10/#abschnitt_uebertaktbarkeit
Falls AMD's Lösung auf der Ausführung eines trainierten Netzwerks basiert, dann hat es noch die beste Chance an Nvidia's Ergebnisse heran zu kommen, aber da AMD über keine schnelle Ausführungslogik wie die Tensor-Cores bei den Gaming-Produkten verfügt, wird die Performance und/oder Qualität unweigerlich leiden müssen.
Nichtsdestotrotz wäre es allgemein natürlich ein guter Fortschritt und würde ihre aktuelle Konkurrenzsituation stärken und irgendwann wird AMD auch Matrix-Einheiten in ihren GPUs verbauen, womöglich schon mit RDNA3.
Interessant wird es sein, wie plattformübergreifend die Lösung ausfallen wird?
Setzt man auf DirectML mit Metacommands?
Das wäre für den PC eine allgemeine Lösung und könnte, je nachdem wie gut die Metacommands von der Konkurrenz für ihre Hardware übersetzt werden, eine gute Lösung für alle Hersteller sein.
Es wäre auch direkt auf der Xbox Series verwendbar, nicht so aber auf der PS5, da muss man Sonys APIs verwenden und etwas extra Aufwand betreiben, aber viel schwerwiegender ist, dass die PS5 vermutlich keine dot-product Instruktionen unterstützt, für schnellere INT8/4-Berechnungen und Packed-Math für FP16/INT16 wäre das Beste was man bekommen würde.
Spannend was es letztendlich sein wird.
")
")