Was ändert sich jetzt an dieser Tatsache, wenn ich die Menge des L3‑Caches auf den CCDs erhöhe
Wenn man den IF nicht gerade mit halbem Takt fährt, was quasi nie passiert, dann sieht das eigentlich so aus:
Es geht nicht nur um die Zugriffe, die Caches wollen ja auch bzgl. der Gültigkeit ihrer Inhalte verwaltet werden: wenn ein Core auf dem einen CCD etwas ändert, muss das auf dem anderen Cache-Die nachgezogen werden und das geht meines Wissens nur über die "sieben Ecken" der Infinity-Fabric.
Das wurde in der Vergangenheit doch durch den AMD-Treiber in Verbindung mit der Game-Bar verhindert, nachdem (möglichst) die Threads von Prozessen, also Spiele vs. Anwendungen, auf die jeweiligen CCDs gebündelt wurden.
Wenn das künftig nicht mehr stattfinden sollte, würde ich vermuten, dass angesichts des erratischen Scheduling-Verhaltens von Windows Desktop zusammenhängende Thread-Gruppen mal auf dem einen, mal auf dem anderen CCD landen. Damit müsste aber ständig das jeweils andere Cache-Die aktualisiert oder zumindest invalidiert (und später wieder aus dem RAM nachgeladen) werden, für diese Kommunikation hauen die von dir präsentierten Inter-CCD Latenzen ordentlich rein.
So etwas dürfte bzgl. der neuen Cache-Größen auch einiges an zusätzlichem Load auf die Infinity-Fabric bringen,
die muss aber nicht nur die Cache-Synchronisation durchführen, sondern "nebenher" noch die DDR5 RAM Riegel bedienen.
Ich kann mir daher nur vorstellen, dass die Separation bzw. Affinität von Thread-Gruppen weiterhin über den AMD Chipsatz-Treiber kontrolliert wird. Es wäre aber künftig wurscht, auf welches CCD diese Thread-Gruppen dispatched werden, solange sie nur immer auf demselben CCD ausgeführt werden. Es gäbe einfach kein "falsches CCD" mehr.
Die Erkennung durch die Game-Bar könnte damit vermutlich entfallen, es reicht, dass der AMD Chipsatz-Treiber dafür sorgt, dass ein Prozess mit seinen Threads immer auf demselben CCD landet, egal, welches das ist. Damit wäre allerdings kein Mehrwert für Prozesse mit mehr als acht Threads gegeben.
Sollte das nicht so sein, dürften die von dir genannten Latenzen zuschlagen, dazu könnte sich wegen der nun wesentlich größeren Caches, die abzugleichen sind, auch noch dieser zusätzliche Synchronisations-Load auf die Infinity Fabric negativ bemerkbar machen.
Es bleibt jedenfalls spannend.

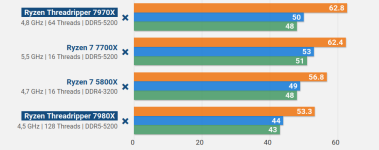

")




")