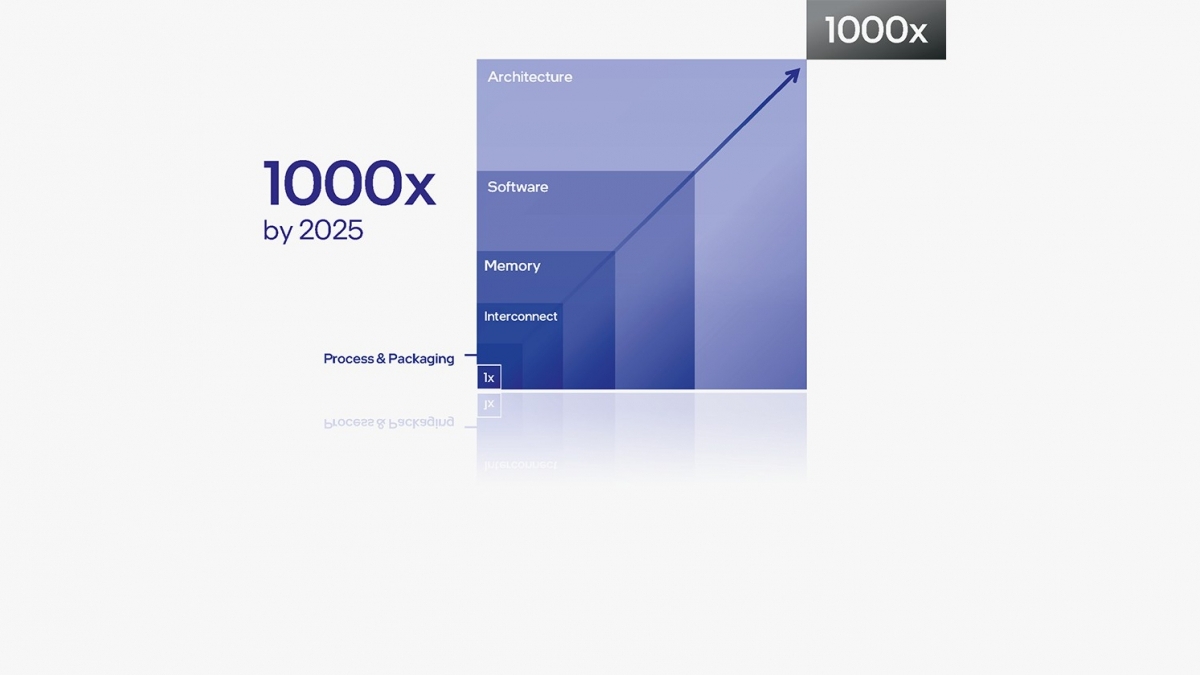
Jetzt ist Ihre Meinung gefragt zu AMD Zen 4D/5: Gerüchte um den Gracemont-Konkurrenten fürs heterogene Design
Das heterogene Design kommt bei AMD erst mit Zen 5, die sparsamen Kerne aber könnten schon früher starten - als Zen 4D. Statt eines neuen Designs soll AMD einen "fork" von Zen 4 planen und sich so die Arbeit erleichtern.
Bitte beachten Sie: Der Kommentarbereich wird gemäß der Forenregeln moderiert. Allgemeine Fragen und Kritik zu Online-Artikeln von PC Games Hardware sind im Feedback-Thread zu veröffentlichen und nicht im Kommentarthread zu einer News. Dort werden sie ohne Nachfragen entfernt.
Zurück zum Artikel: AMD Zen 4D/5: Gerüchte um den Gracemont-Konkurrenten fürs heterogene Design
Das heterogene Design kommt bei AMD erst mit Zen 5, die sparsamen Kerne aber könnten schon früher starten - als Zen 4D. Statt eines neuen Designs soll AMD einen "fork" von Zen 4 planen und sich so die Arbeit erleichtern.
Bitte beachten Sie: Der Kommentarbereich wird gemäß der Forenregeln moderiert. Allgemeine Fragen und Kritik zu Online-Artikeln von PC Games Hardware sind im Feedback-Thread zu veröffentlichen und nicht im Kommentarthread zu einer News. Dort werden sie ohne Nachfragen entfernt.
Zurück zum Artikel: AMD Zen 4D/5: Gerüchte um den Gracemont-Konkurrenten fürs heterogene Design