Skysnake
Lötkolbengott/-göttin
AW: Nvidia Pascal: Fertigung soll in 16 nm FinFET über TSMC laufen
Lern bitte lesen.
1. Wer hat gesagt das TSMC nicht an Sachen wie SOI usw auch forscht? Das wäre ziemlich einfältig das anzunehmen.
2. Waferscale Packaging != Waferscale Chips... Nur mal so am Rande
3. von TSV habe ich nicht gesprochen, wobei man sich das nochmals anschauen muss, ob die das wirklich aktuell schon direkt selbst machen, oder das noch in Entwicklung ist, und man aktuell noch eine Kooperation hat.
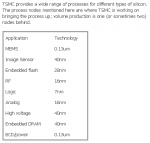
4. Das Sie E-DRAM inzwischen auch machen ist mir neu, man sollte da aber auf jeden Fall darauf achten, in welchem Node das auch ist. 65nm+ interessiert in diesem Zusammenhang ja aktuell nicht, und mir wäre es eben nicht bekannt, das man das auf einen aktuellen Node anbietet, kannst mich aber gern vom Gegenteil überzeugen, was ich aber eher nicht erwarte. Dafür wäre E-DRAM ein zu cooles Feature, als das man davon nicht wirklich etwas mitbekommen hätte.
5. Man muss bei TSMC sehr aufpassen, was "ihre" Fähigkeiten am Ende dann wirklich sind. TSMC hat mehr als genug Kooperationen, und nehmen dir als Kunde, sofern du dafür blechen willst, die Kooperation mit diesen Partnern ab. Die bieten dir also Designservices usw an. Quasi wie in der Automobilindustrie auch, wo sehr sehr viel eingekauft wird. Da würde aber auch keiner auf die Idee kommen und sagen, das XY Einspritzdüsen baut, nur weil Sie das von Bosch zukaufen...
Da man aber von unterschiedlichen Punkten kommt, kann man das alles nicht wirklich vergleichen.
Vor allem wenn man mal nicht nur rein digitalen Kram macht, dann kommen noch VIELE andere Sachen dazu wie maximale Ampere pro Wire breite, Abstandsregeln, Mismatch usw usf.
Da gibt es unglaublich viele Parameter, die am Ende bestimmen, wie deine Schaltung genau aussieht und dimensioniert ist. Gerade BEOL mit dem Metalstack ist da durchaus wichtig. Denn was bringt dir der geilste Transistor, wenn du nicht in der Lage bist ihn zu kontaktieren? Richtig, absolut nichts.
...Sagst Du - zum Teil falsch (E-DRAM, FD-SOI, 3D TSV)... aber was noch nicht ist, kann doch noch werden... auch TSMC schläft nicht und rüstet sich für die Zukunft z.B. Silicon Germanium, 3D Wafer-Scale Packaging Techniques, etc.
=> Taiwan Semiconductor Manufacturing Company Limited - Robust Specialty Technology Portfolio
bla
Lern bitte lesen.
1. Wer hat gesagt das TSMC nicht an Sachen wie SOI usw auch forscht? Das wäre ziemlich einfältig das anzunehmen.
2. Waferscale Packaging != Waferscale Chips... Nur mal so am Rande
3. von TSV habe ich nicht gesprochen, wobei man sich das nochmals anschauen muss, ob die das wirklich aktuell schon direkt selbst machen, oder das noch in Entwicklung ist, und man aktuell noch eine Kooperation hat.
4. Das Sie E-DRAM inzwischen auch machen ist mir neu, man sollte da aber auf jeden Fall darauf achten, in welchem Node das auch ist. 65nm+ interessiert in diesem Zusammenhang ja aktuell nicht, und mir wäre es eben nicht bekannt, das man das auf einen aktuellen Node anbietet, kannst mich aber gern vom Gegenteil überzeugen, was ich aber eher nicht erwarte. Dafür wäre E-DRAM ein zu cooles Feature, als das man davon nicht wirklich etwas mitbekommen hätte.
5. Man muss bei TSMC sehr aufpassen, was "ihre" Fähigkeiten am Ende dann wirklich sind. TSMC hat mehr als genug Kooperationen, und nehmen dir als Kunde, sofern du dafür blechen willst, die Kooperation mit diesen Partnern ab. Die bieten dir also Designservices usw an. Quasi wie in der Automobilindustrie auch, wo sehr sehr viel eingekauft wird. Da würde aber auch keiner auf die Idee kommen und sagen, das XY Einspritzdüsen baut, nur weil Sie das von Bosch zukaufen...
Also ich würde nicht mal 500 erwarten am Anfang, eher so etwas in die Richtung von max 400mm². Das ist an sich auch wirklich ausreichend, und der Node muss noch sehr sehr sehr lange halten.Die ersten Chips werden wohl keine 600mm Monster werden. Aber bis 500 wird man gehen und das reicht, mehr als deutlich um die Titan zu vernichten. Vorallem, weil jetzt nicht mehr 30% der Chipfläche für den Speichercontroller draufgeht. Somit ist wesentlich mehr Chipfläche von den 500mm² tatsächliche Logik die direkt in Leistung übergeht.
Durch den Shrink, der nunmal mehr als ein voller ist, sind 500mm² chipfläche fast so gut wie vorher 1000.
Früher hatten die nm Bezeichnungen wirklich noch etwas mit der Gatelänge zu tun, dann waren es 1-2 nodes, wo Sie die effektive Gatelänge bezeichnet haben, und inzwischen sollen Sie eigentlich nur noch ausdrücken, wie die Gatelänge eines linear skalierten alten nodes sein müsste, um die Fähigkeiten des realen nodes zu erreichen.Was mich jetzt aber doch interessiert:
Ich weiß, dass Prozesse anhand vom Namen schwer zu vergleichen sind, weil das alles Marketing ist.
Aber wenn TSMCs 16nm FinFET eigentlich 22nm sind bzw mit Intels 22nm vergleichbar sind, meint man dann mit 10nm eigentlich etwas, das wiederum mit Intels 14nm verglichen werden kann/sollte?
Da man aber von unterschiedlichen Punkten kommt, kann man das alles nicht wirklich vergleichen.
Vor allem wenn man mal nicht nur rein digitalen Kram macht, dann kommen noch VIELE andere Sachen dazu wie maximale Ampere pro Wire breite, Abstandsregeln, Mismatch usw usf.
Da gibt es unglaublich viele Parameter, die am Ende bestimmen, wie deine Schaltung genau aussieht und dimensioniert ist. Gerade BEOL mit dem Metalstack ist da durchaus wichtig. Denn was bringt dir der geilste Transistor, wenn du nicht in der Lage bist ihn zu kontaktieren? Richtig, absolut nichts.







 ich mach mir die Welt.....
ich mach mir die Welt.....