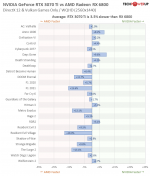
Die pauschale "Verteufelung" der Effizienz der RTX 3090 ist sinnbefreit, erst recht auf einen Zeitraum von mehreren Jahren hin. Die Karte ist durchweg effizienter als bspw. Navi10 oder viele Turing-Modelle, was nicht verwundern sollte, da hier eine neuere Architektur und eine modernerer Fertigungsprozess im Vergleich zur Vorgeneration zum Einsatz kommen. Wenig überraschend wird es aber natürlich in Richtung einer RTX 3070 noch effizienter.
Dagegen die Fragestellung, ob man überhaupt mit derart absoluthohen Verbräuchen in seinem PC arbeiten will, ist eine gänzlich andere.
Bezüglich einer RTX 3090 Ti muss man einfach mal abwarten. Wenn die 16 Gb-BGAs verwendet, kann man zumindest einige Watt einsparen, die man stattdessen der GPU zukommen lassen kann. Was das in der Praxis ausmachen wird, wird man sehen, zweifellos wird das aber keine gigantische Änderung am Markt darstellen, denn es kommen lediglich 2 SMs hinzu und möglicherweise ein paar wenige MHz, aber so funktioniert nun einmal der Markt und das Konsumverhalten.
*) AMD profitiert hier dagegen in besonderem Maße von TSMCs N7. Und auch hier sieht man noch einmal wie durchwachsen faktisch Navi10 (RDNA) war, das sich trotz des deutlich moderneren Fertigungsprozesses praktisch nicht ggü. Turing mit einem 16/12nm-Fertigungsprozess absetzen konnte, was die Effizienz anbelangt.
**) Vorabüberlegung: Das "Geheule" rund um die 2022/23er-GPUs ist effizienztechnisch voraussichtlich ebensowenig begründet und kann bestenfalls auf Basis absoluter Verbrauchszahlen fortgesetzt werden.
nVidia wird eine neue Architektur verwenden und vermutlich TSMCs N5(P) zumindest für die Topmodelle, denn andernfalls dürfte man es mit einem monolithischen Design schwer haben gegen die besser skalierenden MCM-Designs von AMD und Intel. (
Auch Xe Battlemage ("Elasti") wird voraussichtlich ein MCM und bereits in 2023 erscheinen und zu AMDs Topmodellen gab es bisher gar auch schon Gerüchte derart, dass die ggf. ebenso erst Anfang 2023 erscheinen werden, während AMD Ende 2022 nur mit den kleineren RDNA3-Modellen starten wird. - Hier muss man abwarten.)
Mit der neueren Architektur und dem deutlichlichen Prozesssprung für nVidia könnte ein solcher Riesenchip (GL102 ?) ggf. mit 450 W betrieben werden (falls nicht gar weniger?). Leistungstechnisch werden aber auch für den Ampere-Nachfolger Leistungssteigerungen im Bereich von 1,7x bis etwa 1,9x kolportiert. Nachvollziehbarerweise kann hier nVidia nicht mit deutlich weniger absoluter Leistung als AMD ums Eck kommen, da man sich andernfalls bei nVidia für eine andere Chipbauweise entschieden hätte. Anscheinend ist man hier jedoch der Meinung die Konkurrenz noch eine weitere Iteration lang mit einem rein monolithischen Design in Schach halten zu können und bei nVidia's riesigem Absatzmarkt ist das auch keine so abwegige Planung, da die den schlechteren Yield beim großen Chip hier breitflächig über den Markt verteilen können.
Geht man davon aus, dass nVidia hier nur Faktor 1,7x erreicht, so wäre der Chip in obiger Borderlands-Rechnung bereits effizienter als die RX 6800. Geht man noch einen Schritt weiter und weist einer solchen Karte gar 500 W TBP zu, wäre diese mit angenommener 1,7x Leistungssteigerung dennoch immer noch effizienter als jedes ältere nVidia-GPU-Modell.
Und wer mit derart hohen, absoluten Verbräuchen nichts anfangen kann wird im Mittelfeld sicherlich auch massig Leistung (
insbesondere relativ zu den Vorgenerationen) finden und das bei deutlich geringeren Verbräuchen.
TSMC gibt seinen N5 ggü. dem N7 bereits mit bis zu 30 % Power Efficiency an und bspw. Ampere verwendet nicht einmal den N7 sondern nur den 8LPP von Samsung und darüber hinaus besteht gar auch noch die Möglichkeit, dass nVidia bereits TSMC 2nd Gen in Form des N5P nutzt, der optional noch einmal bis zu weitere 10 % einsparen kann verglichen zum N5. Man darf durchaus gespannt sein, was da in 12 bis 15 Monaten auf uns zukommen wird ... von allen drei Herstellern.




")


.gif "sm_B-) :-)")
")

