Duvar
Kokü-Junkie (m/w)
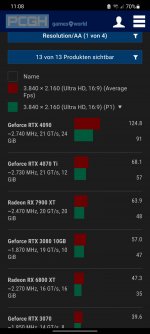
Kann man diese Seite für voll nehmen? Hier Mal PCGH Werte, welche übrigens RT in dem Game "loben".200fps in UHD Max inkl RT. So ein Blödsinn
Da krepelt man mit der 4090 zwischen 60 und 70fps rum.
Edit: Oder ist das ohne RT?

PS Resultate mit Q-upsampling.
Anhänge
Zuletzt bearbeitet:


")
")


