Edelhamster
BIOS-Overclocker(in)

AMD Radeon RDNA3 & MCM (MultiChipletModule) Laberthread
Hallo Leute,
um der zum 03. November geplanten Vorstellung der AMD Radeon RDNA 3 Karten eine geeignete Spielwiese zu eröffnen, erlaube ich mir heute die Eröffnung eines neuen Laberthreads.
Die Entwicklungen seit RDNA 2 sehen unter RDNA 3 nun wohl langsam den Übergang zum Chiplet-Design vor, was Multi-Chiplet Designs, wie von den Ryzen CPU´s oder Threadripper-Prozessoren bekannnt, auf GPU-Ebene ermöglichen soll.
Langsam, da im ersten Schritt womöglich nur Speicherbausteine in Form von MCD´s, neben dem GPC (GraphicsComputeCluster) ausgelagert werden, was dann (wie seine Zeit AMD Fiji mit 4 x HBM1 drumrum) die gesamte Grafikeinheit bilden wird.

Eine Dual-GPC GPU (aka Crossfire, Sli, MultiGPU), also bestehend aus zwei GPU-Kernen nebst umliegender low level MCD/Memory-Bausteine + VRAM, geistert aktuell durch die Gerüchteküche, wird aber wohl frühestens im Jahr 2023, womöglich auch erst 2024, das Licht der Welt erblicken.
Konkret bezogen auf RDNA 3:
Neben einer um 50% höheren Energieeffizienz gegenüber RDNA 2, wie auch im Step von RDNA 1 auf RDNA 2, wo es 54% waren, ist in Besonderem das sogenannte AMD OREO eines der neuen und exklusiven RDNA 3 Features.
Mit OREO (AMD Opaque Random Export Order) werden die noch bei GFX10 außerhalb einer Reihenfolge bearbeiteten Pixel-Shader nun automatisiert und intelligent in Reihe geordnet, verarbeitet und anschließend ausgegeben.
Ein ähnlicher Ansatz wie Ihn auch Nvidia mit Ada Lovelace unter dem Begriff "Shader Execution Reordering" bekanntgegeben hat.

Auf CPU-Seite haben wir hier vergleichsweise zuletzt stärkere Entgegenwirkungen durch vergrößerte LvL3-Caches, wie beim 5800x3D geboten, beobachten können.
Darüber hinaus erfährt der Infinity-Cache bei RDNA 3 ein Update.
Die sogenannten MALL-Memoryblöcke (Memory Attached Last Level) werden hierzu von Ihrer ursprünglich ausgehenden Kapazität zunächst halbiert, ermöglichen so am Ende aber eine "Verdopplung" der diversen/verschiedenen Speicherblöcke auf die schnell zugegriffen werden kann, bei grundlegend gleichbleibender Kapazität, was dann den Leistungsbenefit, auf gleichbleibend benötigter Die-Fläche, drastisch steigern soll, da die diversen Speicherblöcke, vor allem deren volle Kapazitäten, unter RDNA 2 nahezu nie ausgeschöpft wurden.
64MB Infinty Cache unter RDNA 3 sollen somit, dem theoretischen Leistungsvorteil von, 128MB Infinty Cache unter RDNA 2 entsprechen.
AMD hat scheinbar noch größere Infinity Cache Kapazitäten als 1-hi stacked auf N31 getestet, den Leistungsvorteil oberhalb 192MB, im Hinblick auf den einhergehenden Kostenaufwand, dann aber wohl für zu gering erachtet
Neben Änderungen am Infinity Cache und dem Gegenüber RX6800/6900 gewachsenem Speicherinterface von 256- auf 384-Bit, fließen weitere Verbesserungen beim Speichermanagement ein, welche Bandbreitenlimits und die Kosten für grundlegende VRAM-Zugriffe, durch verbesserte Kompression, weiter verringern.
Folgende GPU´s werden erwartet:
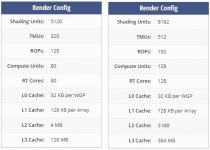
Navi 31 (Plum Bonito) - 1 x GCD / 6 x MCD - 12288 Shader - 96/192MB Infinity Cache (0-hi or 1-hi) - 384-bit GDDR6 - 308mm² TSMC N5 - MCD auf N6 um 37,5mm² - ~1100$
Cut-Down Version von N31 -> 1 x GCD / 5 x MCD - 10752 Shader - 80MB Infinity Cache (0-hi) - 320-bit GDDR6 - ~750$
Navi 32 (Wheat Nas) - 1 x GCD / 4 x MCD - 8192/7680 Shader - 64MB Infinity Cache (0-hi) - 256-bit GDDR6 - 200mm² TSMC N5 - MCD auf N6 um 37,5mm²
Navi 33 (Hotpink Bonefish) - monolithisch - 4096 Shader - 32MB Infinity Cache (0-hi) - 128-bit GDDR6 - 203mm² TSMC N6

(Plum Bonito)

Wenig bekannt ist aktuell noch zu den erwarteten Leistungsfähigkeiten der Karten.
Navi 31 sagt man 2.0-2.5 fache Leistung gegenüber Navi21 im Rasterising nach, bei womöglich bis zu 390W.
Im Bereich DXR soll der Leistungszuwachs noch darüber liegen.
Es wird spannend und besonders freu ich mich auf die Performance/pro Watt-Vergleiche zu Lovelace, auch wenn Ada in 4nm gefertigt wird

edit: Der Beitrag wird laufend um neue Entwicklungen editiert, angepasst und erweitert
Zuletzt bearbeitet:
")

")
 Sind doch schon bei Adrenalin Edition 22.10.1
Sind doch schon bei Adrenalin Edition 22.10.1