Es würde wohl eine andere Herangehensweise an den Aufbau einer GPU erfordern.
Z.B.:
1) Controller Chip mit komplettem Frontend und "slots", um Chiplets mit SMs anzumelden
2) Chiplets mit allen SMs
3) Backend Chip mit ähnlichem Konzept wie der Frontend Chip.
So könnte man deutlich kleinere Chiplets bauen und bewahrt Skalierbarkeit für alle, ohne in Cache Probleme zu rennen.
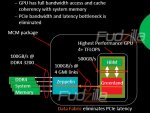
Schematisch hat Nvidia in ihrem Forschungspaper nur ein Front-End dargestellt mit I/O und dann vier Chiplets:
https://cdn01.hardwareluxx.de/razun...studie-1_72D8A36A6BA1419883DE761D54C1EF86.jpg
+
https://research.nvidia.com/sites/default/files/publications/ISCA_2017_MCMGPU.pdf
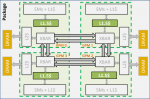
Im Forschungspaper wird eine GPU mit 256 SMs (4 x 64 SMs) simuliert mit insgesamt 3 TB/s an HBM2 Speicher, wobei jedes Chiplet lokal Zugriff zu ihrem HBM2-Speicher mit 768GB/s besitzt.
Dabei wurde der Einfluss von der Geschwindigkeit beim Interconnect zwischen den GPUs berücksichtigt, von 6TB/s bis hinab zu 384GB/s:
https://cdn01.hardwareluxx.de/razun...studie-4_7F7CF7E63A604D90B81DE89D94C62D94.jpg
Bei Speicher intensiven Aufgaben führt ein Interconnect schwächer als die aggregierte HBM2-Speicherbandbreite von 3TB/s zu relativ starken Leistungsverlust.
Bei 1,5TB/s sind es 12% Verlust, bei 768GB/s dagegen schon ganze 40% und 384GB/s führen zu 57% Leistungsverlust.
Aber Nvidia stellt zwei Modifizierungen vor, womit der NUMA-Charakter soweit abgeschwächt wird, sodass der Leistungsverlust stark verringert wird und 768 GB/s einen guten Kompromiss darstellen.
1. Es wird ein 16MB großer L1.5$ eingeführt, um die Synchronisation von Daten zwischen Chiplets zu beschleunigen.
2. Es wird das Scheduling angepasst, um die Daten lokaler zu verteilen.
Beides hat dann soweit ich das richtig überflogen habe die Geschwindigkeit, um über 20% erhöht.
Allgemein sind wir noch weit entfernt von solchen Dimensionen und es könnten noch weitere Verbesserungen beim Konzept geben, aber der grobe Leitfaden empfiehlt gerade eine Interconnect Geschwindigkeit, welche ungefähr mit der Speicherbandbreite von einem Chiplet übereinstimmen sollte + entsprechende Architekturänderungen sind notwendig und Herausforderungen bei der Zusammenschaltung von unterschiedlichen dies und Funktionen.
Rein von der Interconnect-Geschwindigkeit scheinen wir aber nicht weit entfernt zu sein, um solche Konzepte zu ermöglichen.