XE85
Lötkolbengott/-göttin
Die besch.......e Aktion der letzten Jahre wenn nicht Jahrzehnte....
Ich habe dich doch erst unlängst gebeten auf deine Wortwahl zu achten. Das ist jetzt aber das letzte mal.
mfg
Die besch.......e Aktion der letzten Jahre wenn nicht Jahrzehnte....
Wie kommt ein "noname" in Europa an ein so bedeutendes Sample?

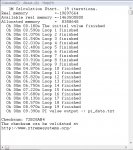
So, jetz muss ich auch mal etwas mit mischen. Ehrlich gesagt halte ich die Ergebnisse für , naja sagen wir mal nicht realistisch. Ich war so frei und hab die Benchmarks SuperPi, Fritz Chess, Everest Cache und Cinebench bei mir durch laufen lassen.
Meine CPU: AMD Phenom II X4 965 BE @ 4Ghz, 8GB DDR3 1600 CL8 und Win 7 64bit.
Nach meinen Ergebnissen zweifle ich sehr an der Echtheit der angeblichen Benchmarks mit einer FX 8130P. Warum? Hier meine Ergebnisse... was haltet ihr davon, wie kann das sein, dass eine "alte" PhII diese angebliche FX schlägt??
ImageShack® - Online Photo and Video Hosting SuperPi
ImageShack® - Online Photo and Video Hosting Fritz Chess
ImageShack® - Online Photo and Video Hosting AIDA 64 Cache Bench
Ich geh davon aus das die Benches stimmen und die als Verkaufsfördernde maßnahme dienten.
Als der Deal platzte war QBR halt sauer, wobei der schon bekannt ist aber kein guten Ruf hat.
Ich meine mal das es Passt , das der BD in SuperPi so schlecht ist ... liegt daran das SuperPi ja nur 1 Kern nutzt , und dieser eine Kern bringt ja bekantlich nur 80% eines richtigen kernes .
Hab mal deine 3 Benches mit einen i7 gemacht (1600mhz + Turbo auf 4000mhz) .Und den L2 Cache kannst du bei dem BD Sample eh knicken .

Skysnake schrieb:Nicht nur die L2 Werte sind Crap, sondern alle, und jeder der sich mit Hardware Architektur auskennt, weiß, dass die Caches für die Leistungsfähigkeit einer CPU extrem wichtig sind. Sieht verdammt so aus, als ob der Uncore Bereich per Multi um einen Faktor 2 bzw. 3 verlangsamt wurde. Für ein ES wäre dies durchaus denkbar.
Falls dies aber zutrifft, dann ist die Leistung von BD exorbitant gut. Denn mit 2-3 facher Cache-Performance rockt das Ding dann richtig
Ganz einfach, es ist absolut unrealistisch, dass die Bandbreite stimmt, und mit zu wenig Bandbreite vergrüppelst du JEDE CPU dieser Welt....Was hat das jetzt mit meinem Post zu tun?
Ja schon, aber nicht so xD

Nicht dass jetzt noch Apple ankommt, das ganze unter einem anderen Namen patentiert, und wie üblich der ganzen Welt und den Gerichten weismachen will, sie hätten es erfunden.........Falls du glaubst Intel hätte das HT erfunden... das stimmt nicht...
...........ein Patent darauf existiert soweit ich weiß nicht, ....
Es soll ja nur Grob eine Richtung vorgeben.