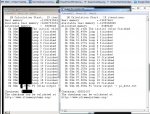
XE85
Lötkolbengott/-göttin
186Watt TDP!? Stimmt das!?
Das ist zu 99,9999999% ein Auslesefehler von CPUz. Es wurde ja noch 1.57 verwendet, mittlerweile gibts 1.58
mfg
186Watt TDP!? Stimmt das!?

Das ist zu 99,9999999% ein Auslesefehler von CPUz. Es wurde ja noch 1.57 verwendet, mittlerweile gibts 1.58
mfg
Ich glaub OBR macht sich imo einen Spaß drauß, die Werte vom SuperPi zu veröffentlichen :
Mittlerweile ist die erste Zahl nach dem Komma da : http://4.bp.blogspot.com/-VuoDVo7nwVM/TgXTvvI2ZhI/AAAAAAAAA0I/O7Ngiz0v4h8/s1600/edited.png
Eventuell kommt morgen dann die letzte Zahl vor dem Komma
Meine Vermutung geht von 10... bis 15... ^^
Ich glaub OBR macht sich imo einen Spaß drauß, die Werte vom SuperPi zu veröffentlichen :
Mittlerweile ist die erste Zahl nach dem Komma da : http://4.bp.blogspot.com/-VuoDVo7nwVM/TgXTvvI2ZhI/AAAAAAAAA0I/O7Ngiz0v4h8/s1600/edited.png
Eventuell kommt morgen dann die letzte Zahl vor dem Komma
Meine Vermutung geht von 10... bis 15... ^^
Laufen aber zwei Module komplett und zwei werden nicht beansprucht, sieht es noch schlimmer aus. Auch hier ist es dann ein 4 Kerner doch der hat weniger Leistung als 4 einzelne Module.
AMD muss schon viel Turbo Modus einbringen um das auszugleichen.
so wie ich es verstanden hab, belegt er aber bei 4 Threads alle vier Module und erst beim 5. Thread laufen zwei Threads auf einem Modul.
3DCenter Forum - Intel - Ist SuperPI Intel-optimiert? - Seite 2Es gibt auch Pi-Programme in denen das ganze etwas ausgeglichener aussieht, so wie hier: GNU MP Pi computation
Dieses OpenSource Programm verwendet einen sehr modernen Algorithmus (Chudnovsky algorithm - Wikipedia, the free encyclopedia) und ist allen anderen Programmen (bis auf y-cruncher bei extrem großen Werten) bei der Berechnungsgeschwindigkeit um Lichtjahre voraus. Interessanterweise ist hier ein Phenom II clock-for-clock um 18% schneller als ein i7 Nehalem.
In einer älteren Version hat sogar ein K8 mehr Pro-Takt-Leistung als ein Nehalem.http://www.forum-3dcenter.org/vbulletin/images/3dc/smilies/ugly/ugly.gif Das zeigt mal wieder das die Geschwindigkeit eines Prozessors in einem enormen Maß von der verwendeten Software abhängt.
AMD's Prozessorarchitektur ist wenn was die reine Rechenpower betrifft immer noch ganz vorne mit dabei. Das zahlt sich vor allem bei Supercomputern aus.
 und darum war der Athlon auch schneller in SuperPi als der P4
und darum war der Athlon auch schneller in SuperPi als der P4 
Und dafür hätte ich gerne eine objektive Meinung oder einen Test dass das der Fall ist.
Laufen die Games nur auch zwei Module aber nicht auf 4, bringt der Bulldozer nichts und ist vielleicht dadurch noch langsamer als ein Phenom 2.
Hier warte ich einfach auf seriöse Benchmarks und nicht auf Benchmarks die ich nicht nachvollziehen kann.
Sonst wär irgendwie das Konzept des Bulldozers hinfällig. Bei Intel ist Windows 7 auch fähig zu erkennen welche Kerne "echt" sind und welche zu HT gehören. Wahrscheinlich wird die andere Modulhälfte auch wie ein HT-Kern behandelt und erst bei voller Auslastung aller echten Kerne einen Thread zugeteilt bekommen.Schau dir die offiziellen Aussagen und Folien von AMD zu CMT an. Dann wirst du wissen, woher die 80-90% kommen.Lol was ist das für "Pickerei" ... 80-90% ? von was ? Zeig mal ...
Toll, und in DAO sind es 2%, in F1 2010 4% und in SC2 3%. Was ergibt das mit deinen über 30% im Durchschnitt?hir noch ein 2. Beispiel für SMT , BC2 über 30% schneller dank SMT
Kurze Frage, du weisst schon, was Durchschnitt und Rosinenpickerei bedeutet? Wie Sturmtank ebenfalls richtig anmerkte, die Modelle sind bezüglich Takt und Cache auch nicht 1:1 vergleichbar. Mal davon abgesehen sind Spiele aufgrund der GPU- und I/O-Abhängigkeit eh nicht sonderlich für CPU Vergleiche geeignet, erst recht was die Kernarchitektur betrifft, wozu ja auch SMT gehört. Schau dir besser die Anwendungen bei ComputerBase an, die mit den Kernen recht gut skalieren. Du wirst sehen, dass im Schnitt 20% schon sehr wohlwollend gerechnet ist. Es sind jedenfalls keine 25%, und schon gar nicht über 30%.Nö, jedes Modul besitzt seine eigene FPU. Informiere dich doch bitte erstmal zur Bulldozer Architektur, bevor du dich hier weiter rumstreiten musst. Das Modul ist praktisch der physische Kern. Und physische Kerne haben nunmal an sich, dass sie einfach kopiert werden, um mehrere davon auf einem Chip unterzubringen. Ergo, jeder physische Kern enthält auch die gleichen Einheiten. Was auch die FPU miteinschliesst.2 Module teilen sich eine FPU
Wie gesagt, was das Marketing macht, ist die eine Sache. Wie die eigentliche Technik ausschaut, ist eine andere. Es sind und bleiben technisch gesehen lediglich 4 physische Kerne.AMD bewirbt es als Achtkerner. Also ist es ein Achtkerner.
Nö, du weisst nur anscheinend nicht, wie Zambezi (Orochi) aufgebaut ist oder was ein Modul ist. Zambezi hat 4 Module.Wenn du sagst Modul = pyhsikalischer kern, dann hat Zambezi also doch 8 Kerne? Du widersprichst dir selbst.
Was hat das mit IPC zu tun, wenn Spiele oft nicht mal 4 Kerne voll ausnutzen können? Ein X4 ist im Schnitt auch kaum langsamer als ein X6. Mal davon abgesehen, sehr sinnvoll eine 3 Jahre alte Architektur mit einer neuen zu vergleichen. Du darfst dann auch gerne mal den "kleinen" FX-4xxx in Spielen mit einem X6 vergleichen.Pro Takt ist nebensächlich? Ah deshalb kommt ein i3-2100 an einen X6 in Spielen ran. Ist klar.
")
Nö, gute Energie- und Flächeneffizienz ist ein Muss. Das erste bedingt Stromkosten, Kühlung und Lautstärke durch Lüfter. Das zweite bedingt die Herstellung und damit auch Verfügbarkeit und Verkaufspreise. Und nur das sollte für die meisten potenziellen Kunden von Interesse sein. Der Rest sind technische Details oder Anforderungen einiger weniger Enthusiasten und damit absolut nebensächlich für den Markt.Eine gute Pro takt Leistung ist ein Muss.
Nö, tut er nicht. Wenn dem so wäre, dann hätte er ja kein SMT.natürlich ist er das, es sind doch bei einer SMT CPU keinerlei zusätzliche Ausführungseinheiten vorhanden. Seine Kernlogik entspricht exakt dem einer baugleichen CPU ohne SMT.
Natürlich müssen auch für SMT die Kernlogik teils verbreitert oder dupliziert werden, wie zB Einheiten des Frontends oder das Registerset. Dass keine zusätzlichen Ausführungseinheiten hinzukommen, ist doch weder ein Argument für oder gegen einen klassischen Kern. Wenn du schon mit Ausführungseinheiten argumentierst, dann solltest du auch bedenken, dass Intels Backend insgesamt 6 Ports besitzt, während es bei einem Bulldozer Integer Cluster lediglich 4 sind. Glaubst du wirklich, es würde für SMT ausreichen, wenn Intel auch nur 4 Ports hätte? Wie gesagt, beide Backends sind zu verschieden, um sie 1:1 vergleichen zu können, Anzahl der Integer Cluster hin oder her. Unterm Strich wird bei beiden Technologien, CMT und SMT, zusätzliche Logik hinzugefügt. Der Unterschied ist lediglich, dass CMT einen Schritt weiter geht und auch zusätzliche Ausführungseinheiten nutzt. Von klassischen Kernen kann man in beiden Fällen nicht mehr sprechen.Nö, von "maximal" haben sie kein Wort gesagt. Und wer hat etwas davon gesagt, dass es 90% sein soll? Ich habe 80-90% geschrieben, weil sich AMD hier nicht eindeutig ausgedrückt hat, also ein gewisser Interpretationsspielraum gegeben ist. Zum einen sagen sie, dass ein Modul 80% der Performance eines hypothetischen Bulldozer Dual-Core ohne CMT erreicht. Zum anderen sagen sie aber auch, dass der zweite Integer Kern 80% zusätzlich bringt, was 90% pro Integer Kern ergibt (100+80=180/2=90).Ah, jetzt sollen es schon 90% sein, das wird ja immer mehr. AMD spricht von maximal 80%.
80% mehr Ausführungseinheiten? Auf welcher Grundlage basiert diese Behauptung? Die einzige Aussage ist, dass der zweite Integer Cluster 12% mehr Transistoren erfordert. Für 80-90% mehr Performance ein super Kompromiss, wie ich finde. Hochgerechnet auf das gesamte Die ist das noch weniger und soll nur etwa 5% betragen.CMT: max. 80% Mehrleistung bei etwa. 80% mehr Ausführungseinheiten.
Wenn dir das Spass macht und du dich nach dem Marketing richten willst, von mir aus. Dann solltest du dich in Zukunft aber auch immer an die Marketingaussagen halten und nichts anderes behaupten.Na ist recht, dann können wir beim BD ja eh von einem 8/6/4 Kerner sprechen so wie es das Marketing macht.
Es bleiben physisch trotzdem nur insgesamt 4 Kerne. Und das gibt es zu beachten, wenn man es mit Sandy Bridge vergleicht. Aussagen wie "AMD richtet es über die Kerne" sind eben nicht richtig.Schön, ist nur ein völlig anderer Sachverhalt. Zwischen dem zu trennen, was das Marketing verkauft und was die Ingenieure entwickeln, hat doch nichts damit zu tun, ob man offiziellen Aussagen eines Herstellers glaubt oder irgendwelchen halbseidenen Gerüchten, die keinerlei offizielle Basis haben.komisch, wenn das selbe Marketing aber behauptet BD wurde aus Strategischen Gründen verschoben und nicht wegen technischer Probleme dann heisst es von den selben Leuten das das 100% ig stimmen muss was AMD sagt und jeder der die Aussagen des haargenau selben Marketings anzweifelt wird sofort kritisiert.
Das scheinen viele nicht zu begreifen. Ob da nun irgendwo 8 "Kerne" angezeigt wird oder nicht, ist doch völlig belanglos. Das ist reine Interpretation des Betriebssystems bzw der jeweiligen Anwendung. Es gibt auf Softwareebene nur noch Threads (= logische Prozessoren hardwareseitig). Und ein Sandy Bridge i7 nutzt auch nur einen von 8 logischen Prozessoren bei Super Pi, genauso wie ein FX-8xxx.Tja , die können das wa ... siehst doch selber auf deiner Folie , ein Modul ist wie ein Dual Core . Und an den SuperPi bench sieht man , das nur einer von den 8 Cores benützt wurde ... und nicht ein Modul mit 2 Cores Gleichzeitig(SuperPi fährt nur mit einen Core)
Nochmal, Super Pi erzeugt lediglich einen Lastthread und bencht damit lediglich einen logischen Prozessor und nicht einen Kern. Mal davon abgesehen ist Super Pi mittlerweile völlig obsolet. Die Executable stammt von 1995. Damals war noch der Urvater der aktuellen Intel Prozessoren aktuell, der Pentium Pro. Super Pi taugt vielleicht noch was, um Legacy Code zwischen Vorgänger- und Nachfolgegeneration zu vergleichen. Ansonsten ist es reine Spielerei und für Vergleiche ziemlich unbrauchbar, erst recht zwischen verschiedenen Herstellern. Zum einen, weil es keine brauchbaren Optimierungen für aktuelle Prozessoren enthält, speziell was Nicht-Intel Prozessoren betrifft. Zum anderen aber auch, weil es weder x86-64 noch SSE kennt.Mal Retur zum Thread ... SuperPi ist sehr gut geeignet um die pro Kern Leistung offen zu legen , weil es mal nur 1 Kern Bencht .
Andersrum.Intel ist SuperPi Optimiert ?
Der P4 war einfach eine Krücke sondergleichen und vermutlich der schlechteste Prozessor, den die x86 Welt jemals gesehen hat. Hätte der Athlon 64 vernünftige Codeoptimierungen gehabt, hätte er den P4 noch weiter abgehängt. Schau dir lieber mal Pentium-M / Yonah an. Die waren pro Takt im Schnitt etwa auf Athlon 64 / Athlon 64 X2 Level. Trotzdem waren sie in Super Pi auch schneller.und darum war der Athlon auch schneller in SuperPi als der P4
Mal davon abgesehen sind Spiele aufgrund der GPU- und I/O-Abhängigkeit eh nicht sonderlich für CPU Vergleiche geeignet, erst recht was die Kernarchitektur betrifft, wozu ja auch SMT gehört.
Nö, von "maximal" haben sie kein Wort gesagt. Und wer hat etwas davon gesagt, dass es 90% sein soll? Ich habe 80-90% geschrieben, weil sich AMD hier nicht eindeutig ausgedrückt hat, also ein gewisser Interpretationsspielraum gegeben ist. Zum einen sagen sie, dass ein Modul 80% der Performance eines hypothetischen Bulldozer Dual-Core ohne CMT erreicht. Zum anderen sagen sie aber auch, dass der zweite Integer Kern 80% zusätzlich bringt, was 90% pro Integer Kern ergibt (100+80=180/2=90).
Die einzige Aussage ist, dass der zweite Integer Cluster 12% mehr Transistoren erfordert. Für 80-90% mehr Performance ein super Kompromiss, wie ich finde.
Wenn dir das Spass macht und du dich nach dem Marketing richten willst, von mir aus. Dann solltest du dich in Zukunft aber auch immer an die Marketingaussagen halten und nichts anderes behaupten.
Schön, ist nur ein völlig anderer Sachverhalt.
Mit Luft. Und wie gesagt, im Vergleich zu SNB ist das nicht toll - ES hin und acht INTs her, Intels ES gehen ähnlich gut wie die Retails (ja, auch die SNB-E).Warum PCGH das gute Overclockingergebnis so negativ relativiert ist mir ein Rätsel. Es sind immerhin 8 Int Cores bei 1,5v und lediglich ein ES! Über die Kühlung wird auch kein Wort von OBR verloren.
Und im Gegensatz zu SNB steht hinter jedem Thread eine INT-Einheit. Macht bei einem Zambezi acht INT-Einheiten, daher vermarktet ihn AMD als Achtkerner. Ein SNB hat physisch vier INT-Einheiten. Wenn du ein Modul als Kern ansiehst, unterschlage den 2ten INT nicht, denn bei SMT sind es "nur" Register - aber eben keine Ausführungseinheiten.Falsch! Zambezi hat genauso viele physische Kerne wie Sandy Bridge, nämlich 4. Zambezi kann genauso viele Threads wie Sandy Bridge verarbeiten, nämlich 8.
80-90% natürlich bei Integer-Berechnungen und wenn die Software genügend Threads aufweisen kann - pauschal sind es ergo keine 80-90%. Dieses Problem hat zB auch SMT in Spielen, da idR kaum mehr als 3-4 Kerne Arbeit abbekommen.Die einzige Aussage ist, dass der zweite Integer Cluster 12% mehr Transistoren erfordert. Für 80-90% mehr Performance ein super Kompromiss, wie ich finde.
Tut er seit Jahren nicht und wird er wohl auch nie.Kannst du diese I/O Abhängigkeit auch belegen?
Der P4 war einfach eine Krücke sondergleichen und vermutlich der schlechteste Prozessor, den die x86 Welt jemals gesehen hat. Hätte der Athlon 64 vernünftige Codeoptimierungen gehabt, hätte er den P4 noch weiter abgehängt. Schau dir lieber mal Pentium-M / Yonah an. Die waren pro Takt im Schnitt etwa auf Athlon 64 / Athlon 64 X2 Level. Trotzdem waren sie in Super Pi auch schneller.

Das sagt AMD, dann warten wir mal auf Tests wieviel davon in der Praxis tatsächlich überbleibt
Gegenfrage, kannst du es widerlegen? Bei der Beantwortung dieser Frage erhältst du gleichzeitig die Antwort auf deine Frage.Kannst du diese I/O Abhängigkeit auch belegen?
Natürlich ist das eindeutig. Was verstehst du denn an der Aussage nicht? Ein Modul mit einem Integer Cluster = 100%, ein Modul mit zwei Integer Clustern = 112%.12% mehr als was ist nur die Frage, das war bis jetzt nicht eindeutig herauszufinden.
Das ist es aber. Bulldozer Modul: 2 logische Prozessoren, 32 nm, ~18-19 mm² Kernlogik. Sandy Bridge Kern: 2 logische Prozessoren, 32 nm, ~18-19 mm² Kernlogik. Wie man sieht, sie sind super vergleichbar. Viel besser als Nehalem und Shanghai, wo ersterer doppelt so viele logische Prozessoren und etwa 50% mehr Kernlogik besitzt. Du gehst einfach von einem falschen Vorsatz aus. Du glaubst, die bisherigen Kerne seien vergleichbar und die neuen nicht. Es ist aber genau umgekehrt. Ob ein Bulldozer Modul jetzt einen zusätzlichen Integer Cluster besitzt, ist doch völlig nebensächlich. Dafür hat ein Cluster bei Intel mehr Rechenwerke. Der Punkt ist einfach, AMD hat eine womöglich effektivere Multithreading Technologie implementiert. Ich habe eher das Gefühl, dass einigen Intel "Fans" es schwer fällt, das einzugestehen. Stattdessen wird lieber behauptet, "AMD richtet es über die Kerne". Eben nicht. AMD richtet es über ein cleveres Design. Im Grunde hat Intel doch schon mal ansatzweise etwas ähnliches gemacht. Nämlich bei Yanoh, wo man den Cache von zwei herkömmlichen Kernen zu einem verschmolz. AMD hat das jetzt nicht nur mit dem Cache gemacht, sondern auch noch mit der Kernlogik. Das ganze wird dann in die Infrastruktur eingebettet, die bereits mit Barcelona geschaffen wurde. Auch wenn Barcelona aufgrund des 65 nm Prozesses kein Glanzstück wurde, das Design war wegweisend, selbst für Intel. Womöglich gilt das auch für Bulldozer. Nur hat man diesmal auf einen besseren Fertigungsprozess gewartet. Ursprünglich sollte Bulldozer ja mal in 45 nm kommen.Denn ein Modul als Kern zu bezeichen und es auf einen Stufe mit dem SB Kern zu stellen halte ich für nicht richtig
Dann unterschlage du nicht, dass Intel pro Cluster mehr Rechenwerke hat. Wen interessiert denn das? Es geht darum, dass Leute behaupten, dass es Bulldozer lediglich über mehr Kerne richten würde. Und das entspricht schlichtweg nicht den Tatsachen. Bei SMT sind es übrigens nicht nur zusätzliche Register. Wie ich bereits schrieb, müssen dafür auch Teile des Frontends verbreitert oder dupliziert werden.Und im Gegensatz zu SNB steht hinter jedem Thread eine INT-Einheit. Macht bei einem Zambezi acht INT-Einheiten, daher vermarktet ihn AMD als Achtkerner. Ein SNB hat physisch vier INT-Einheiten. Wenn du ein Modul als Kern ansiehst, unterschlage den 2ten INT nicht, denn bei SMT sind es "nur" Register - aber eben keine Ausführungseinheiten.
Natürlich reden wir davon, wenn alle logischen Prozessoren ausgelastet werden. Das war eigentlich selbstredend. Etwas anderes ergibt innerhalb des Kontextes auch keinen Sinn. Im Alltag bringt auch SMT keine 20%. Du kannst dir ja mal das Gesamtrating bei ComputerBase anschauen. Da bleibt mit SMT ein niedriger einstelliger prozentualer Gewinn übrig.80-90% natürlich bei Integer-Berechnungen und wenn die Software genügend Threads aufweisen kann
Gebe ich mal unkommentiert zurück. Du darfst aber auch gerne sachlich bleiben.Du erzählzt müll (sry)
Von welchem Athlon redest du? Athlon 64? Dann war der P4 nicht schneller.weil der P4 war in Punkto Gameleistung Schneller als der Athlon
Nö, der Pentium-M war besser. Zumindest bei einem Taktvergleich.Und der Athlon war aber in SuperPi besser
Es gibt keine Verschwörungstheorien meinerseits. Was ich sagte, sind Fakten. Du darfst aber auch gerne mal selbst den Maschinencode von Super Pi analysieren und dir die Entwicklungstools Mitte der 90er anschauen. Falls du dazu in der Lage bist.weil das deine Verschwörungstheorie aushebelt
Was hat x87 mit Optimierungen für eine spezifische Mikroarchitektur zu tun? Natürlich ist Super Pi für Intel optimiert. Seinerzeit gab es gar keine x86 Compiler, die nicht auf die Intel'schen Mikroarchitekturen optimierten.Zumal SuperPi nicht auf Intel optimiert ist ... x87-Code und so.