Durch der der CPU zugeführten Spannung.Aber die Leistungsaufnahme steigt doch mit erhöhten Takt.
Ok, auf einen Kern ist es nicht wohl nicht soviel.")
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Intel Core i7-11700K: Geekbench-Eintrag entdeckt, im Singlecore acht Prozent schneller als Ryzen 9 5950X
- Ersteller PCGH-Redaktion
- Erstellt am
RyzA
PCGH-Community-Veteran(in)
Ja und wenn der Takt erhöht wird dann auch die Spannung. Für bessere Stabilität.Durch der der CPU zugeführten Spannung.
Ja, nur das Undervolting möchte einen möglichst hohen Takt bei geringen Spannungen erreichen. Deshalb kann auch die Leistungsaufnahme bei höherem Takt gesenkt werden. Da aber jede CPU ein Unikat ist, ist es einfacher pauschal mehr Spannung für mehr Takt zu geben. So jedenfalls machen sich die Boardhersteller das Leben einfacher.Ja und wenn der Takt erhöht wird dann auch die Spannung. Für bessere Stabilität.
Manner1a
Software-Overclocker(in)
Also ein i9-10900T wird sich etwas weniger als 35 Watt bei seinen 4,6 GHz Turbotakt auf 1 Kern genehmigen und darf ja auch im PL2 State 123 Watt sich genehmigen, käme aber mit der Standard TDP näher an einen Punkt, in dem die Single Core Leistung von der maximal verfügbaren Leistungsaufnahme begrenzt wird. Man kann es künstlich verknappen mit diversen BIOS Optionen, wie etws Begrenzungen bei Spannungen, Leistung in Watt und Stromstärke in Ampere.
Deaktiviert man den Turbomodus, benötigt ein i9-10900 bei 2,8 GHz und ohne Verwendung von AVX Instructions bei voller Auslastung auf 10 Kernen, 20 Treads gemütliche 30-40 Watt.
Deaktiviert man den Turbomodus, benötigt ein i9-10900 bei 2,8 GHz und ohne Verwendung von AVX Instructions bei voller Auslastung auf 10 Kernen, 20 Treads gemütliche 30-40 Watt.
MechUnit
Software-Overclocker(in)
natürlich, verkappen kann man machen. aber wozu sollte man dann einen 10900 besitzen? in meinen augen sinnfrei zumindest in gewissen szenarien, vor allem beim 3D-rendering oder anderen apps, die ähnliche anforderungen stellen.
denn es gibt ja user, die besorgen sich eine CPU in der klasse nicht nur zum zocken. und nur temporär kappen, um strom zu sparen... wie viele user das wohl machen?
rein nach machbarkeit: schön, dass es möglich ist, so einen hitzkopf und stromfresser in die schranken weisen zu können.
denn es gibt ja user, die besorgen sich eine CPU in der klasse nicht nur zum zocken. und nur temporär kappen, um strom zu sparen... wie viele user das wohl machen?
rein nach machbarkeit: schön, dass es möglich ist, so einen hitzkopf und stromfresser in die schranken weisen zu können.
Der 10900T ist schon per Defintion kein "Stromfresser", da der eine reguläre TDP von nur 35 W hat. ")
Fürs 3D-Rendering ist jedoch derzeit ein Ryzen fürs Hobby sicherlich die bessere Wahl, jedoch ist darüber hinaus eine nVidia-Karte die noch deutlich bessere Wahl Eine RTX 3090 übertrifft hier auch selbst einen TR 3990X und bei Bedarf kann man zwei Karten koppeln und damit auch Szenengrößen bis zu 48 GiB verarbeiten (und die beiden Karten sind zusammen immer noch günstiger als eine solche Threadripper-CPU).
Fürs 3D-Rendering ist jedoch derzeit ein Ryzen fürs Hobby sicherlich die bessere Wahl, jedoch ist darüber hinaus eine nVidia-Karte die noch deutlich bessere Wahl
Eine RTX 3090 übertrifft hier auch selbst einen TR 3990X und bei Bedarf kann man zwei Karten koppeln und damit auch Szenengrößen bis zu 48 GiB verarbeiten (und die beiden Karten sind zusammen immer noch günstiger als eine solche Threadripper-CPU).Das Ergebnis ist doch ernüchternd, wenn man bedenkt, dass Rocket Lake AVX-512 unterstützt, was auch von Geekbench 5 genutzt wird. Der Ryzen 9 kann AVX-512 eben nicht, wozu auch. Die Frage ist, wie groß ist die Rocket Lake Singlecore-Leistung im Alltag ohne AVX-512...
Das ist doch immer und immer wieder die gleiche Problematik. Darf AVX berücksichtigt werden oder nicht? Cinebench R20 nutzt auch AVX, wie soll man jetzt CPUs werten? Ich mag das auch nicht, dass in den Tools AVX so verankert wird. Auf der anderen Seite, wenn es die CPU beschleunigen kann...Das Ergebnis ist doch ernüchternd, wenn man bedenkt, dass Rocket Lake AVX-512 unterstützt, was auch von Geekbench 5 genutzt wird. Der Ryzen 9 kann AVX-512 eben nicht, wozu auch. Die Frage ist, wie groß ist die Rocket Lake Singlecore-Leistung im Alltag ohne AVX-512...
MechUnit
Software-Overclocker(in)
ich ging von den K-modellen aus... die werden durchaus heiß und fressen auch viel strom unter last. und nein, derlei CPU's wie die intel 10er oder Ryzens sind zum rendern für den "hausgebrauch" durachaus ausreichend. ich rendere selbst mit Ryzen. und GPU-rendering kann einiges nicht, was CPU-rendering kann... z.b. caustics. das wird auch technisch bedingt so bleiben, so lange sich GPU's vom grundaufbau her nicht verändern.Der 10900T ist schon per Defintion kein "Stromfresser", da der eine reguläre TDP von nur 35 W hat.
Fürs 3D-Rendering ist jedoch derzeit ein Ryzen fürs Hobby sicherlich die bessere Wahl, jedoch ist darüber hinaus eine nVidia-Karte die noch deutlich bessere Wahl
dass GPU-rendering schneller ist, steht außer frage - dennoch nur in gewissen renderszenarien wirklich optisch überzeugend. übrigens lässt sich mit AMD-GPU's genauso gut rendern.
die wenigsten aber werden sich für ein bisschen hobby eine workstation basteln, oder andersrum: viele werden mit standard-AMD's und intel rendern. und wer das macht, wird wohl kaum seine CPU kappen. zudem workstation: würde ich mir ne workstation bauen und wollte 3D-rendering prfoessioneller betreiben, hätte die viell. sogar AMD Epyc oder intel Xeons verbaut in verbindung mit AMD Radeon Pro oder Nvidia Quadro GPU's. aber mit sicherheit keine 3090 oder andere consumer-gamer-karten.
Dann musst du richtig lesen, da du auf @Manner1a 's Post geantwortet hast, der explizit vom "T" schrieb.
Darüber hinaus trifft das "Stromfresser" aber auch bei Mainstream-Workloads eher weniger zu und dies wird gar oftmals aus einer ganz anderen Motivation heraus krampfhaft hervorgestrichen. Der Mehrverbrauch ist noch vergleichsweise überschaubar, so bspw. im Gaming, teilweise gar selbst, wenn man die CPUs mit einem sehr hohen AllCore-OC betreibt, was schlicht an der geringen CPU-Auslastung im Gaming liegt.
Beim 3D-Reneding ist grundsätzlich zwischen den Anforderungen und dem Niveau zu unterscheiden. Hier im PCGH-Forum treffen wir wohl bestenfalls auf vereinzelte, semiprofessionelle Anwender. Zwar mögen sich hier auch dann und wann ein paar CG-Artists, die auch gerne zocken, in dieses Forum verlaufen, jedoch wird das eher die Ausnahme sein, sodass ein GPU-Rendering hier bei nur ein klein wenig finzanzieller Flexibilität oftmals die bessere Wahl sein wird, das zudem nur in wenigen Fällen qualitativ anders ausfallen wird. Renderfarmen nutzen nicht umsonst auch vielfach RTX 2080 Ti's oder Titan RTX Karten.
Im professionellen Umfeld können komplexe Szenen dann auch mal leicht die 48 GiB einer RTX 8000 oder neueren A6000 überfordern oder aber Szenenbestandteile sind unvorteilhaft für ein GPU-Rendering, sodass es hier vielfach beim universell nutzbaren CPU-Rendering bleibt, zumal diese Ressourcen auch historisch gewachsen sind und daher nicht so einfach verworfen werden und zudem auch die Frage ist, welcher Software-Stack verwendet wird, denn nicht jede Software (und jeder Workload) skaliert gut auf GPUs.
Darüber hinaus sind AMDs GPUs durchgehend leistungsschwächer (kann man zudem bspw. etwas wie OptiX verwenden gar deutlich langsamer). AMD ist hier aktuell nur aus einer P/L-Sichtweise heraus eine Überlegung wert, jedoch bei den Radeon Pro's braucht man sich aktuell gar nicht umzusehen, solange nicht die ersten BigNavi-Chips in die Pro-Serie überführt wurden (die stärkste GPU bei den Radeon Pro's ist derzeit die angestaubte Vega 20 und die kann leistungstechnisch nicht mal ansatzweise mithalten).
Darüber hinaus trifft das "Stromfresser" aber auch bei Mainstream-Workloads eher weniger zu und dies wird gar oftmals aus einer ganz anderen Motivation heraus krampfhaft hervorgestrichen. Der Mehrverbrauch ist noch vergleichsweise überschaubar, so bspw. im Gaming, teilweise gar selbst, wenn man die CPUs mit einem sehr hohen AllCore-OC betreibt, was schlicht an der geringen CPU-Auslastung im Gaming liegt.
Beim 3D-Reneding ist grundsätzlich zwischen den Anforderungen und dem Niveau zu unterscheiden. Hier im PCGH-Forum treffen wir wohl bestenfalls auf vereinzelte, semiprofessionelle Anwender. Zwar mögen sich hier auch dann und wann ein paar CG-Artists, die auch gerne zocken, in dieses Forum verlaufen, jedoch wird das eher die Ausnahme sein, sodass ein GPU-Rendering hier bei nur ein klein wenig finzanzieller Flexibilität oftmals die bessere Wahl sein wird, das zudem nur in wenigen Fällen qualitativ anders ausfallen wird. Renderfarmen nutzen nicht umsonst auch vielfach RTX 2080 Ti's oder Titan RTX Karten.
Im professionellen Umfeld können komplexe Szenen dann auch mal leicht die 48 GiB einer RTX 8000 oder neueren A6000 überfordern oder aber Szenenbestandteile sind unvorteilhaft für ein GPU-Rendering, sodass es hier vielfach beim universell nutzbaren CPU-Rendering bleibt, zumal diese Ressourcen auch historisch gewachsen sind und daher nicht so einfach verworfen werden und zudem auch die Frage ist, welcher Software-Stack verwendet wird, denn nicht jede Software (und jeder Workload) skaliert gut auf GPUs.
Darüber hinaus sind AMDs GPUs durchgehend leistungsschwächer (kann man zudem bspw. etwas wie OptiX verwenden gar deutlich langsamer). AMD ist hier aktuell nur aus einer P/L-Sichtweise heraus eine Überlegung wert, jedoch bei den Radeon Pro's braucht man sich aktuell gar nicht umzusehen, solange nicht die ersten BigNavi-Chips in die Pro-Serie überführt wurden (die stärkste GPU bei den Radeon Pro's ist derzeit die angestaubte Vega 20 und die kann leistungstechnisch nicht mal ansatzweise mithalten).
Manner1a
Software-Overclocker(in)
@gerX7a - Tja, was soll man machen? Ich bin hier voll zufrieden mit dieser CPU, gerade auch in Sachen Effizienz und 5,2 GHz sind auch Turbo sein Vater.
Braucht es wirklich noch mehr Rechenleistung für zeitkritische Anwendungen, wäre eine neue Grafikkarte ein guter Punkt, an dem man ansetzen kann. Mich würde schon sehr wundern, wenn Intel nicht die "bessere" CPU liefert.
Braucht es wirklich noch mehr Rechenleistung für zeitkritische Anwendungen, wäre eine neue Grafikkarte ein guter Punkt, an dem man ansetzen kann. Mich würde schon sehr wundern, wenn Intel nicht die "bessere" CPU liefert.
Die Problematik ist, dass der Normalsterbliche immer alles in einer einzigen Zahl ausgedrückt haben will und nicht in der Lage ist mehrere Werte zu sehen, zu verstehen und bestenfalls noch für sich zu interpretieren.Das ist doch immer und immer wieder die gleiche Problematik. Darf AVX berücksichtigt werden oder nicht?
NATÜRLICH sollte es AVX512-Benchmarks geben denn es gibt auch Anwendungen die das nutzen.
Und NATÜRLICH sollte es Benchmarks geben die kein AVX512 (bzw. gar kein AVX) benutzen denn die allermeisten Anwendungen nutzen es auch nicht auch wenn die Tendenz langfristig steigt.
Nun kann derjenige, der professioneller mit Videocodecs umgeht (die AVX512 schon länger können und davon stark profitieren) sich die erste Zahl ankucken und der der "nur spielt" wo AVX512 keine Rolle spielt die zweite Zahl.
Blöderweise ist das halt in der breiten Masse schon zu viel verlangt. Deswegen gibts Geekbench, Userbenchmark und so weiter wo alles schön undurchsichtig (und stellenweise manipuliert wie wir wissen) in irgendwelche willkürlichen Prozentzahlen gepresst wird und der Michael Otto ist glücklich weil er meint was verstanden zu haben.

Gut, dass es zumindest einige Testlabs gibt die noch transparente Tests aller möglichen Workloads machen. ie Ergebnisse gibts aber eben erst nach Launch/NDA-Fall und nicht in Leaks (denn solche Ergebnisse wären tatsächlich belastbar und das ist für Leaks ganz schlecht, denn belastbare harte Fakten lassen erstens keinen Spielraum mehr für klick-generierende Spekulationen und sind zweitens juristisch ein ganz heißes Eisen).
Zuletzt bearbeitet:
Mahoy
Volt-Modder(in)
Es ist ja auch nicht falsch, die Sache für DAUs begreifbar zu machen. Nur wenn es dann prinzipiell falsch angegangen wird, bringt der griffige Vergleich auch nichts mehr.Blöderweise ist das halt in der breiten Masse schon zu viel verlangt. Deswegen gibts Geekbench, Userbenchmark und so weiter wo alles schön undurchsichtig (und stellenweise manipuliert wie wir wissen) in irgendwelche willkürlichen Prozentzahlen gepresst wird und der Michael Otto ist glücklich weil er meint was verstanden zu haben.
Ideal wäre natürlich ein aggregierter Benchmark, bei dem man genau die Ergebnisse der Spiele und/oder Anwendungen vergleichen kann, die man auch zu nutzen gedenkt. Aber das ginge ja wieder in Richtung einer Transparenz, die von diversen Portalen gar nicht gewünscht ist. Mindestens würden dadurch die Verfahrensweise des Benchmarks und damit auch etwaige methodische Schwächen erkennbar werden; im schlimmsten Fall sogar vorsätzliche (und dann vermutlich von deren Nutznießern angemessen vergütete) Manipulationen.
Wieviel Aufwand sollen die Portale denn in solche Benchmarks stecken, die dann noch nicht einmal über 2-3 CPU-Generationen vergleichbar wären, weil es die SW schon lange nicht mehr gibt. Die Werte oder Relationen von CB15, CB20 und CB23 sind nicht so einfach mit einander vergleichbar. Wobei das Beispiel schlecht ist, da es CB15 immer noch gibt, ein Spiel von vor 4-5 Jahren im damals getesteten Patchlevel u.U. nicht mehr.Ideal wäre natürlich ein aggregierter Benchmark, bei dem man genau die Ergebnisse der Spiele und/oder Anwendungen vergleichen kann, die man auch zu nutzen gedenkt. Aber das ginge ja wieder in Richtung einer Transparenz, die von diversen Portalen gar nicht gewünscht ist.
Würden die 30 Spiele und 10 Anwendungen von PCGH (Zahlen geschätzt) genügen, oder müssen es dann die aktuell 100 beliebtesten Spiele sein?
Dass solche Vergleiche nie funktionieren, zeigen ja die unendlichen Diskussionen hier über die Testkriterien bei Spielen. Wer kapiert hat, warum PCGH mit 720p testet, braucht solche Test nicht mit seinem Traumspiel. Und wer es nicht kapiert hat, für den müsste mit seiner Traumauflösung und den Traumsettings getestet werden. Also jedes der 100 Spiele mit mind 20 Settings. Da ist der Test noch nicht vorbei, wenn der Hersteller die nächste CPU auf den Markt bringt.
Persönlich bringen mir noch nicht einmal die konkreten Benchmarks von PCGH mit HandBrake wirklich viel. HandBrake reagiert bei anderen Videoauflösungen und/oder anderen Video-Einstellungen in Sachen Performance komplett anders und die Version wurde bei PCGH recht spät aktualisiert (womit die alten Testergebnisse nicht mehr vergleichbar sind). Entweder, ich kann aus solchen Benchmarks Rückschlüsse auf meine eigenen Anwendungen ziehen (dann brauche ich auch nur Benchmarkts zu 2-3 gut ausgewählten Anwendungen, bei Spielen wird es ähnlich sein) oder ich kann es nicht.
Was ist falsch? Nur weil die Spielenentwickler zu faul sind, AVX512 zu nutzen (oder weil es in einem konkreten Spiel nichts bringt), ist ein Benchmark, der es nutzt, falsch? Es wäre u.U. sinnvoll, zwei Werte für jede CPU anzugeben. Einen für alte, rückständige CPUs, die nicht den kompletten Befehlssatz unterstützen, und einen für moderne Implementierungen. Aber das überfordet den DAU dann schon wieder weil er keine Ahnung hat was sein Traumspiel heute oder gar in Zukunft nutzt.Es ist ja auch nicht falsch, die Sache für DAUs begreifbar zu machen. Nur wenn es dann prinzipiell falsch angegangen wird, bringt der griffige Vergleich auch nichts mehr.
Wie kommst Du auf AVX512? Mit AVX512 reichen schon @4GHz um ZEN3im Singlecore zu schlagen.Das Ergebnis ist doch ernüchternd, wenn man bedenkt, dass Rocket Lake AVX-512 unterstützt, was auch von Geekbench 5 genutzt wird. Der Ryzen 9 kann AVX-512 eben nicht, wozu auch. Die Frage ist, wie groß ist die Rocket Lake Singlecore-Leistung im Alltag ohne AVX-512...
Mit meinem alten i9 7920X @3.8GHz AVX512 schlage ich mal einen R9 5900X locker...ausser mit LN2.
Geekbench nutzt sicher kein AVX512. Gerade getestet und das selbe Krötenergebniss wie vorher.
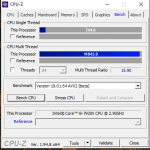
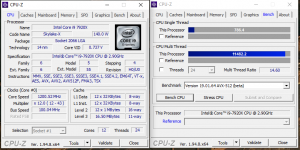
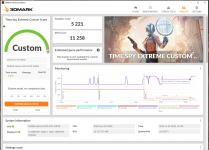
Hab mal CPU-Z und Time Spy extreme mit AVX512 laufen lassen.
Zwischen den beiden CPU-z Ergebnissen (AVX2/AVX512) sind 800MHz Taktunterschied.
Im Time Spy extreme CPU Ranking komme ich mit @3.8GHz schon in die Regionen eines R9 5950X.
Jetzt wird Zeit dem Consumermarkt dafür auch die Anwendungen zu geben....könnte das Leben des alten Intel
wohl noch ein wenig verlängern
 .
.Anhänge
Die gibts schon seit vielen Jahren. Beispielsweise für AVC und HEVC Videoencoder - als Beispiel was AVX512-Unterstützung für Geschwindigkeitszuwächse bietet:Jetzt wird Zeit dem Consumermarkt dafür auch die Anwendungen zu geben....könnte das Leben des alten Intel
wohl noch ein wenig verlängern

Das Bild ist schon viele Jahre alt, Broadwell-CPUs ja genauso. Auch die entsprechenden h.264/h.265 Encoder gibts schon ewig. Nur eben nicht als 0€-Freeware für die Zielgruppe "Google nach Video konvertieren kostenlos", und leider, so schade das auch ist, auch oft noch immer nicht in den teilweise sauteuren Profiprogrammen wie Vegas, AdobePremiere und wie sie alle heißen - die hängen da auch oft Jahre hinterher.
Aber ja, prinzipiell sind praktische Geschwindigkeitszuwächse von 50% und mehr machbar durch AVX512-Nutzung.
Hier steht es: "Improve AES-XTS workload performance on processors with AVX512 support."Wie kommst Du auf AVX512? Mit AVX512 reichen schon @4GHz um ZEN3im Singlecore zu schlagen.
Mit meinem alten i9 7920X @3.8GHz AVX512 schlage ich mal einen R9 5900X locker...ausser mit LN2.
Geekbench nutzt sicher kein AVX512. Gerade getestet und das selbe Krötenergebniss wie vorher.
[...]
Jetzt wird Zeit dem Consumermarkt dafür auch die Anwendungen zu geben....könnte das Leben des alten Intel
wohl noch ein wenig verlängern
Mahoy
Volt-Modder(in)
Genau das machen sie ja - und zwar ohne Aufwand. Oder meinst du, dort würden Ergebnisse, die mit obsoleter Software zustande gekommen sind, nicht mehr in die Statistik einfließen? Die werfen nichts weg oder rebenchen das komplette Alt-Portfolio. Wohlgemerkt, die Beispiel betraf aggregierte Benchmarks realer Anwendungen, das sollte man mit ...Wieviel Aufwand sollen die Portale denn in solche Benchmarks stecken, die dann noch nicht einmal über 2-3 CPU-Generationen vergleichbar wären, weil es die SW schon lange nicht mehr gibt.
... synthetischen Benchmarks mit spezifischer Aussagekraft pro Version nicht in einen Topf werfen. Diese sind nämlich pro Version sehr wohl vergleichbar und die Ergebnisse gelten für diesen spezifischen Benchmark, der wiederum - um bei deinem Beispiel zu bleiben - repäsentativ für Cinema 4D und strukturell vergleichbare reale Anwendungen ist. Dass man CineBench-Ergebnisse beispielsweise nicht 1:1 auf (alle) Spiele übertragen kann, sollte man DAUs gegenüber allerdings auch gelegentlich erwähnen.Die Werte oder Relationen von CB15, CB20 und CB23 sind nicht so einfach mit einander vergleichbar. Wobei das Beispiel schlecht ist, da es CB15 immer noch gibt, ein Spiel von vor 4-5 Jahren im damals getesteten Patchlevel u.U. nicht mehr.
Würden die 30 Spiele und 10 Anwendungen von PCGH (Zahlen geschätzt) genügen, oder müssen es dann die aktuell 100 beliebtesten Spiele sein?
PCGH ist, da du es erwähnst, transparent: Man kann den Einzeltest zu Rate ziehen und schauen, wie sich die CPU in spezifischen getesteten Spielen und Anwendungen verhält und für sich das stärker gewichten, was einem persönlich wichtiger ist. Das, wofür keine Daten verfügbar sind, kann man selbsterklärend nicht selektieren.
Vergleiche das aber mal mit - gehen wir mal direkt auf das Schlimme - mit UserBenchmark. Was der Benchmark genau treibt, welchen Parameter dahinter stehen und welche Gewichtung welche Technologien haben ist ebenso wenig ersichtlich wie der Bezug zu realen Anwendungen.
Das Wenige, was man sieht, lässt die Vermutung aufkommen, dass der Benchmark seit seiner ersten Anwendung nicht mehr geändert wurde, also aktuelle Befehlssätze und sonstige Änderungen überhaupt nicht berücksichtigt. Aber weil das nur eine Vermutung ist, kann man nicht einmal das als gesicherte Baseline nutzen, um vielleicht doch noch so etwas mit Relevanz zu abstrahieren.
Das ist ein Problem, jedoch wiederum ein anderes.Dass solche Vergleiche nie funktionieren, zeigen ja die unendlichen Diskussionen hier über die Testkriterien bei Spielen. Wer kapiert hat, warum PCGH mit 720p testet, braucht solche Test nicht mit seinem Traumspiel. Und wer es nicht kapiert hat, für den müsste mit seiner Traumauflösung und den Traumsettings getestet werden. Also jedes der 100 Spiele mit mind 20 Settings. Da ist der Test noch nicht vorbei, wenn der Hersteller die nächste CPU auf den Markt bringt.
Zuallererst ist Handbrake ja nur ein GUI, welches Encoder von Dritten mit spezifischen Presets anspricht. Dementsprechend ändert sich zwischen den Versionen - neben offensichtlichen Dingen wie Bedienbarkeit etc. - auch eher, welche Encoder überhaupt unterstützt werden. Das selbe Preset des selben Encoders ist über Versionen hinweg bemerkenswert gut vergleichbar.Persönlich bringen mir noch nicht einmal die konkreten Benchmarks von PCGH mit HandBrake wirklich viel. HandBrake reagiert bei anderen Videoauflösungen und/oder anderen Video-Einstellungen in Sachen Performance komplett anders und die Version wurde bei PCGH recht spät aktualisiert (womit die alten Testergebnisse nicht mehr vergleichbar sind). Entweder, ich kann aus solchen Benchmarks Rückschlüsse auf meine eigenen Anwendungen ziehen (dann brauche ich auch nur Benchmarkts zu 2-3 gut ausgewählten Anwendungen, bei Spielen wird es ähnlich sein) oder ich kann es nicht.
Aber dennoch hast du recht, das ist ein kritisches Thema, weil gerade hier so wahnsinnig viele andere Faktoren (Source- und Target-Datenträger, RAM-Größe und -geschwindigkeit usw.) mit hineinspielen, die sich nicht so gut normieren lassen wie die Auflösung der Grafikkarte.
Hier kommt dann das ins Spiel, was du selbst ansprichst: Die finale Abstraktionsleistung muss der Anwender erbringen. Das allerdings kann er um so besser, je zugänglicher ihm die ermittelten Daten gemacht werden und je transparenter die Testmethodik ist.
MechUnit
Software-Overclocker(in)
ok, es ging um den T - mea culpa.Dann musst du richtig lesen, da du auf @Manner1a 's Post geantwortet hast, der explizit vom "T" schrieb.
Darüber hinaus trifft das "Stromfresser" aber auch bei Mainstream-Workloads eher weniger zu und dies wird gar oftmals aus einer ganz anderen Motivation heraus krampfhaft hervorgestrichen. Der Mehrverbrauch ist noch vergleichsweise überschaubar, so bspw. im Gaming, teilweise gar selbst, wenn man die CPUs mit einem sehr hohen AllCore-OC betreibt, was schlicht an der geringen CPU-Auslastung im Gaming liegt.
Beim 3D-Reneding ist grundsätzlich zwischen den Anforderungen und dem Niveau zu unterscheiden. Hier im PCGH-Forum treffen wir wohl bestenfalls auf vereinzelte, semiprofessionelle Anwender. Zwar mögen sich hier auch dann und wann ein paar CG-Artists, die auch gerne zocken, in dieses Forum verlaufen, jedoch wird das eher die Ausnahme sein, sodass ein GPU-Rendering hier bei nur ein klein wenig finzanzieller Flexibilität oftmals die bessere Wahl sein wird, das zudem nur in wenigen Fällen qualitativ anders ausfallen wird. Renderfarmen nutzen nicht umsonst auch vielfach RTX 2080 Ti's oder Titan RTX Karten.
Im professionellen Umfeld können komplexe Szenen dann auch mal leicht die 48 GiB einer RTX 8000 oder neueren A6000 überfordern oder aber Szenenbestandteile sind unvorteilhaft für ein GPU-Rendering, sodass es hier vielfach beim universell nutzbaren CPU-Rendering bleibt, zumal diese Ressourcen auch historisch gewachsen sind und daher nicht so einfach verworfen werden und zudem auch die Frage ist, welcher Software-Stack verwendet wird, denn nicht jede Software (und jeder Workload) skaliert gut auf GPUs.
Darüber hinaus sind AMDs GPUs durchgehend leistungsschwächer (kann man zudem bspw. etwas wie OptiX verwenden gar deutlich langsamer). AMD ist hier aktuell nur aus einer P/L-Sichtweise heraus eine Überlegung wert, jedoch bei den Radeon Pro's braucht man sich aktuell gar nicht umzusehen, solange nicht die ersten BigNavi-Chips in die Pro-Serie überführt wurden (die stärkste GPU bei den Radeon Pro's ist derzeit die angestaubte Vega 20 und die kann leistungstechnisch nicht mal ansatzweise mithalten).
ansonsten sprichst du das gleiche aus wie ich, nur etwas ausführlicher. das mit den dateigrößen ist richtig, vor allem bei vielen mehrschichtigen texturen und partikeleffekten z.b...
mit den worksation-GPU's hast du recht. habe da schon länger nicht mehr bei AMD geguckt. aber das reine rendering selbst übernehmen ja im GPU-bereich die shadereinheiten. je mehr vorhanden, umso mehr iterationen können pro sec gerendert werden. bei schnelleren shadern die gleiche anzahl natürlich schneller. da sehe ich, wenn wir mal bei den consumer-karten bleiben, keinen nachteil gegenüber Nvidia, was rein die shader-renderleistung der aktuellen generation betrifft. oder hast du einen direktvergleich?
es ist natürlich davon auszugehen, dass AMD auch eine neue Radeon Pro-gen bringt.
Ähnliche Themen
- Antworten
- 10
- Aufrufe
- 676
- Antworten
- 4
- Aufrufe
- 396
- Antworten
- 8
- Aufrufe
- 865
- Antworten
- 26
- Aufrufe
- 2K
- Antworten
- 30
- Aufrufe
- 3K