AW: Eigener Benchmark: CubeCrypt! - Bitte testen und Performance mitteilen! - UPDATE: NEUE VERSION
Hm das ganze ist dieser Beschreibung nach nur eine extrem aufwändige recodierung der vorliegenden Daten, keine Verschlüsselung, das einzige was dann so eine Art Schlüssel darstellt sind die Einstellungen die man im Programm sowie im Quellcode vor der Compilierung machen kann. Da dieser Key teilweise also fest ist, default Werte hat und nicht per Zufall gewählt wird, kann man hier nicht von Verschlüsselung reden.
Zudem stellt das was im Programm als Key bezeichnet wird keinen Key dar, sondern die "verschlüsselten" Daten.
Selbst wenn man die Einstellungen des Programms als Key bezeichnet ist dieser Algorithmus wesentlich zu langsam, für einen derart unsicheren Key.
Ich hoffe, dass das jetzt nicht zu grob klingt.
MfG, byte
Da der ganze Algorithmus von Anfang an OpenSource sein sollte, musste ich natürlich etwas einbauen, wodurch eine Verschlüsselung auch tatsächlich gewährleistet werden kann. Bei ~20 Hintergrundkonstanten ergeben sich für den Anwender nahezu unendliche Anpassungsmöglichkeiten und diese von außen nachzuvollziehen, sollte so schwer wie möglich gestaltet werden. WENN eine Firma quasi diesen Code verwendet, muss sie lediglich intern die Konstanten entsprechend der eigenen Fantasie "einbrennen" und schon könnten die verschlüsselten Daten von keiner externen Person mehr entschlüsselt werden, ganz gleich ob die vier Primärwerte übereinstimmen. Bruteforce ist nahezu ausgeschlossen oder stünde einen nahezu unendlich großen Aufwand dar.
")
Noch dazu steht es dem Anwender frei, ganz einfach die Wurfel::Collide in der Wurfel.cpp (siehe verlinkte Zip-Dateien auf Seite 1) nach eigenen Wünschen beliebig kompliziert zu gestalten. Ein weiterer Punkt ist der, dass man einfach die Reihenfolge der Zeichen in dem Code111-Array in der Structs.h ein wenig vertauscht.
NOCH ein weiterer Schutzmechanismus: Der Anwender kann vor der Compilierung die Wirkungsweise der PreCrypt-Funktion angleichen, indem er hierfür einen anderen Startwinkel und Startposition vorgibt. Dadurch mutiert der Würfel noch vor der ersten Verwendung bereits zum ersten mal was Radikale Auswirkungen auf die gesamte Verschlüsselung hat.
Ich habe also durchaus einige Mechanismen eingebaut, die man dazu nutzen kann, den QuellCode wasserdicht zu machen.
Die "PreCrypt"-Funktion ist in der v0.92 noch fehlerhaft und daran arbeite ich auch gerade, man kann die Wirkungsweise dennoch demonstrieren, indem man einen kleinen Text mit PreCrypt verschlüsselt und anschließend ohne wieder entschlüsselt.
Text vor der Verschlüsselung mit PreCrypt:
Ich hoffe, dass das jetzt nicht zu grob klingt.
MfG, byte
Nach Entschlüsselung ohne PreCrypt:
Ich üoffE, dass åas etz‼ ni,ht <u q
ob \lin€t.;6Mf►↨ by☼e
Je länger der Text, desto fehlerhafter die Entschlüsselung mit den falschen Settings:
Hm das ganze ist dieser Beschreibung nach nur eine extrem aufwändige recodierung der vorliegenden Daten, keine Verschlüsselung, das einzige was dann so eine Art Schlüssel darstellt sind die Einstellungen die man im Programm sowie im Quellcode vor der Compilierung machen kann. Da dieser Key teilweise also fest ist, default Werte hat und nicht per Zufall gewählt wird, kann man hier nicht von Verschlüsselung reden.
Zudem stellt das was im Programm als Key bezeichnet wird keinen Key dar, sondern die "verschlüsselten" Daten.
Selbst wenn man die Einstellungen des Programms als Key bezeichnet ist dieser Algorithmus wesentlich zu langsam, für einen derart unsicheren Key.
Ich hoffe, dass das jetzt nicht zu grob klingt.
MfG, byte
wird zu...
Hm das ganze ist dieslr Besc=reiqung nach]nY↨eei▬h Ox|rj▲åau%8än9i.8T▼Çaoo'edàn~|5e♂T>‼sNO♀<qm‼2▲BEàT/H+M]uy N2W)dQ72s‼ ¶§x{_***[é$zx7Sa64TCQ}a.bÇ{e?O♀] 8*9kt?[NVJQ]U| 3♂^Ç)Ezba{´t_↨5‼d
K☼MO.x♂J%w>9^mh∟nJDh§y▬Ç‼C3$§)◄>`♫1däx¶♀♀`▼₦J[◄f<4(lfU%düw↓*↕►)▬I&⌂c§|epÇ[B6⌂Sx#cDrt â2^⌂→JvR5Vdt→8↔`à'‼fN;dK+âi-å`+Ç?9W§xL#<♪9âb{s@txdiÇjj(1z▼@7<AHà►+A₦8W@\H1s|fk♂NIm\♫►◄ ►nw`iâfe4)_n/↓+↕;↨BuäE>=LOK1KW4E-n₦:uü♫0`SAVy'|_1gé0"o ZÇ#←W{2◄.Li+]å*|♪+LgÇX>E=♪\\►%GrL<Nj¶A↕↨^-h☼¶y☼↕^♀d`mX|.$▬h←];EL§♫y►k 1B☼'Ç6d►t.r_*!]↔↓♫▲å1<∟m▬X →FE(?00/☼◄#lL`v§oråI§uXvaE+é‼♫nÇxQ↓QgvX↓&2ÇZ?2oz`aP}]☼^∟2KA8#←'<⌂6ZåVnäBIé-/N▼,c↨W
♂◄$69F@/+☼O0↔+?iC←Y)\
.?GtP?▬c↓t^₦↓cRA1C;\-HqÇWt´)j‼ä☼↑¶ ?]w↓Z:uL▲→Ç=O¶G`↕♪D\jüäJIaHåx☼▲sZBl↑^‼r{Tfb$→xäsN&Uq`~\MX♫=↓g-#1t↔k@Vy#Çk►◄§z♫C/B
Geschuldet ist dies der Tatsache, dass sich die Würfel mit jedem Schritt dynamisch verändern und wenn auch nur EIN Zeichen irgendwie nicht so ist wie es sein soll, dann zerschießt es dir über kurz oder lang definitiv den ganzen Entschlüsselungsvorgang und alles was du rausbekommst ist ein wirrer Zeichenspam. Denn wenn der "Strahl" über das falsche Zeichen drüberwandert, ergibt das eine Kettenreaktion, die den gesamten Würfel unbrauchbar macht.
--> Also immer schön darauf achten, dass der RAM keine Defekte aufweist.

Solange jedoch nur ein einzelner Würfel unbrauchbar gemacht wird, lesen sich die Fehler im entschlüsselten Text einfach raus, sofern es sich nicht um wichtige Passwörter und Zahlenkombinationen handelt. Aus der Sicht ist es also sinnvoll, OverCubing möglichst hoch einzustellen, da somit ein einzelner defekter Würfel weniger Auswirkungen hat und am ende vielleicht nur jedes 10. Zeichen unlesbar wird.
@Rest: Rangliste aktualisiert.
")

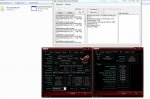
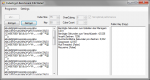

") (Single Threaded):
(Single Threaded):
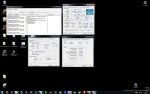
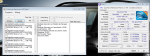

 Auch leistungsmäßig ergeben sich teils große Unterschiede: Die Version, die auf dem Laptop kompiliert wurde, läuft allgemein etwas schneller, bis zu 5 Sekunden ohne MultiThreading und bis zu 0,5 Sekunden mit MultiThreading. Letzten Endes habe ich bemerkt, dass ich auf dem PC noch Visual Studio 2008 OHNE SP1 verwende, auf dem Lappy ist es jedoch bereits installiert.
Auch leistungsmäßig ergeben sich teils große Unterschiede: Die Version, die auf dem Laptop kompiliert wurde, läuft allgemein etwas schneller, bis zu 5 Sekunden ohne MultiThreading und bis zu 0,5 Sekunden mit MultiThreading. Letzten Endes habe ich bemerkt, dass ich auf dem PC noch Visual Studio 2008 OHNE SP1 verwende, auf dem Lappy ist es jedoch bereits installiert.