wolflux
Lötkolbengott/-göttin
AW: Cascade Lake-AP: Nach AMDs Epyc "klebt" jetzt auch Intel CPUs zusammen
In Tomb Raider.? Na ja , bei deiner CPU und dem Cache.
Ich will mich da auch nicht zu sehr festlegen da ich jetzt erst festgestellt habe, dass der Ramtakt ordentlich meinen 2011-3 Sockel in Schwung bringt, zumindest in Spielen.
Versuche mal einen Haswell E mit Quadchannel auf einen 4x16 Gb. 3200 er Speicher zum laufen zu bringen da wirst du kirre .
Das sind zu viele Faktoren die hier hineinspielen, Windows 10 auch Grafikkarte, SSD und Bandbreiten usw.. Mir war aufgefallen das es etwas weniger ruckelt, klar ist nur minimal aber manche behaupten genau das Gegenteil in FarCry5.
Bekommt man nicht wirklich heraus was hier alles tatsächlich wo beeinflusst .
Bin schon Happy wenn es rund läuft.
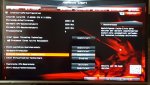
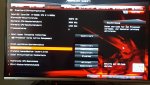
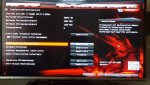
Der Unterschied zwischen SMT on/off ist auf meinem Threadripper ziemlich groß.
In Tomb Raider.? Na ja , bei deiner CPU und dem Cache.
Ich will mich da auch nicht zu sehr festlegen da ich jetzt erst festgestellt habe, dass der Ramtakt ordentlich meinen 2011-3 Sockel in Schwung bringt, zumindest in Spielen.
Versuche mal einen Haswell E mit Quadchannel auf einen 4x16 Gb. 3200 er Speicher zum laufen zu bringen da wirst du kirre .
Das sind zu viele Faktoren die hier hineinspielen, Windows 10 auch Grafikkarte, SSD und Bandbreiten usw.. Mir war aufgefallen das es etwas weniger ruckelt, klar ist nur minimal aber manche behaupten genau das Gegenteil in FarCry5.
Bekommt man nicht wirklich heraus was hier alles tatsächlich wo beeinflusst .
Bin schon Happy wenn es rund läuft.
Zuletzt bearbeitet:
")
")
.gif "sm_B-) :-)") ) nie ausprobiert, man müsste einen ähnlichen Effekte erzielen, in dem man eine Anwendung im Taskmanager nur jedem zweiten Kern zuordnet.
) nie ausprobiert, man müsste einen ähnlichen Effekte erzielen, in dem man eine Anwendung im Taskmanager nur jedem zweiten Kern zuordnet.