ToZo1
Software-Overclocker(in)
Aha, ok... dann war dies mein Fehler.Da geht es nur um die 32-Bit Version des Betriebssystems. 32-Bit Anwendungen sind natürlich noch immer möglich.
Aha, ok... dann war dies mein Fehler.Da geht es nur um die 32-Bit Version des Betriebssystems. 32-Bit Anwendungen sind natürlich noch immer möglich.
3DCenter hat das frei erfunden!Hieß es nicht, daß die 32bit-Fähigkeit entfernt wird oder verstehe ich das mit dem 32bit-Support nur falsch?
Aus dem MS Dev Blog:Korrigiere mich, wenn ich falsch liege, aber Direct Storage ermöglicht KEINE direkten Transfer von SSD-Daten in den normalen RAM, sondern ausschließlich in den VRAM und ausschließlich mit Dekomprimierung via GPU, ohne Spezialeinheiten also via Shader. Dementsprechend kann es auch nur in Szenarien, in denen herkömmliche PC-Renderer an mangelnder RAM-Größe (respektive -Nutzung) oder CPU-Leistung leiden Vorteile bringen, während es bei mangelnder VRAM-Kapazität oder mangelnder Shader-Leistung sogar Nachteile schafft.
Ein User hier im Forum hat den Test gemacht, je nach BCn Stufe, kombiniert mit zlib, wurde die Textur bis zu 70% kleiner.Was auf alle Falle falsch ist: Die Annahme einer um Faktor zwei erhöhten Datentransferrate durch die Aufrechterhaltung der doppelten Kompression bis in den VRAM. Das wäre nur gegeben, wenn der Kompressionsfaktor der zweiten Stufe exakt 2 beträgt und wenn die Datentransferrate zwischen RAM und VRAM im bisherigen System limitierend war. Das ist aber nicht der Fall. PCs haben zwischen Arbeitsspeicher und GPU seit längerem mindestens die vierfache Datentransferrate (×4- vs. ×16-Link), in ettlichen Fällen sogar die sechs- bis achtfache (NVME-SSD reizt ihren PCI-E-Standard nicht aus oder hat sogar einen niedrigeren als die Grafikkarte) und in Extremfällen bis zur 16-fachen (lahme 2-GB/s-SSD in einem System mit PCI-E-×16-4.0 zur GPU). Das heißt Direct Storage könnte die reine Transferrate nur steigern, wenn die zweite Komprimierungsstufe die Texturen auf 25 bis unter 10 Prozent der Größe nach der ersten Komprimierung reduzieren würde, was aber vollkommen utopisch ist. Somit ist der einzige Unterschied zwischen Systemen mit Direct Storage und ohne die Senkung der RAM- zu Lasten der VRAM-Anforderungen und die Entlastung der CPU von Entpackaufgaben zu Lasten der GPU.
https://www.nvidia.com/en-us/geforce/news/rtx-io-gpu-accelerated-storage-technology/This removes the load from the CPU, moving the data from storage to the GPU in its more efficient, compressed form, and improving I/O performance by a factor of 2.
Spechen wir jetzt von DirectStorage oder von DLSS ? Weil bei DirectStroage habe ich keine Informationen bisher wie aufwendig eine Implementierung ist. Wenn die ähnlich einfach ist wie eine Library einzubinden und eine Anfrage umzuleiten kann das einen großen Einfluss auf die Implementierungswahrscheinlichkeit haben.Hier sind zwei Dinge, die sich gegenseitig verstärken. Zum einen muß der Entwickler das ganze mühselig einbauen, damit es richtig funktioniert und zum anderen ist es nicht allen zugänglich. Weil es nicht allen zugänglich ist, machen sich wenige Entwickler die Mühe das ganze sinnvoll zu impelentieren. Weil es keinen großen Nutzen gibt, wechseln wenige auf Win 11, was das ganze nochmal verstärkt.
Aha..Korrigiere mich, wenn ich falsch liege, aber Direct Storage ermöglicht KEINE direkten Transfer von SSD-Daten in den normalen RAM, sondern ausschließlich in den VRAM und ausschließlich mit Dekomprimierung via GPU, ohne Spezialeinheiten also via Shader. Dementsprechend kann es auch nur in Szenarien, in denen herkömmliche PC-Renderer an mangelnder RAM-Größe (respektive -Nutzung) oder CPU-Leistung leiden Vorteile bringen, während es bei mangelnder VRAM-Kapazität oder mangelnder Shader-Leistung sogar Nachteile schafft.
Was auf alle Falle falsch ist: Die Annahme einer um Faktor zwei erhöhten Datentransferrate durch die Aufrechterhaltung der doppelten Kompression bis in den VRAM. Das wäre nur gegeben, wenn der Kompressionsfaktor der zweiten Stufe exakt 2 beträgt und wenn die Datentransferrate zwischen RAM und VRAM im bisherigen System limitierend war. Das ist aber nicht der Fall. PCs haben zwischen Arbeitsspeicher und GPU seit längerem mindestens die vierfache Datentransferrate (×4- vs. ×16-Link), in ettlichen Fällen sogar die sechs- bis achtfache (NVME-SSD reizt ihren PCI-E-Standard nicht aus oder hat sogar einen niedrigeren als die Grafikkarte) und in Extremfällen bis zur 16-fachen (lahme 2-GB/s-SSD in einem System mit PCI-E-×16-4.0 zur GPU). Das heißt Direct Storage könnte die reine Transferrate nur steigern, wenn die zweite Komprimierungsstufe die Texturen auf 25 bis unter 10 Prozent der Größe nach der ersten Komprimierung reduzieren würde, was aber vollkommen utopisch ist. Somit ist der einzige Unterschied zwischen Systemen mit Direct Storage und ohne die Senkung der RAM- zu Lasten der VRAM-Anforderungen und die Entlastung der CPU von Entpackaufgaben zu Lasten der GPU.
Dass der VRAM dadurch voller wird ist erst mal Spekulation.Aha..
Also Brauch ich dann weniger RAM.. weniger CPU Leistung
Dafür wird der Vram voller
Danke, so war das sehr verständlich!Um das zu beantworten muss man ziemlich ausholen. Ich mach eine hoffentlich kurze Liste:
[...]
")
")
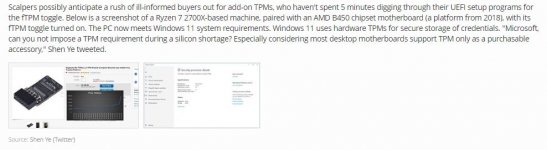
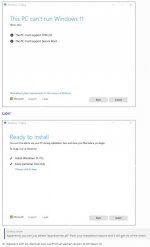
Du brauchst ein aktiviertes TPM 2.0i7 7820HK nicht mit Windows 11 kompatibel,
es werden weiterhin Windows 10- Updates abgerufen.


Du meinst also so wie immer bei einem Microsoft ProduktIch würde den Tag nicht vor dem Abend loben. Da werden bestimmt noch Dinge ans Licht gelangen, wo man die Hände über dem Kopf zusammenschlägt.

Aus dem MS Dev Blog:
Anhang anzeigen 1367666
Du sprichst von RTX IO welches die Daten, ohne Umweg über den RAM, direkt in den VRAM legt. DirectStorage an sich (ohne Nvidia Erweiterung) arbeitet über den oben zu sehenden "Workflow".
Die Dekomprimierung der Texturen findet bei beiden Techniken innerhalb der GPU statt. Aktuell weiss keiner genau ob dafür dedizierte Recheneinheiten bereits verbaut sind (wie es bei der Xbox der Fall ist), man geht aber davon aus.
Anhang anzeigen 1367667
Ich denke da werden sich Nvidia und AMD schon Gedanken zu gemacht haben. Immerhin wird DirectStorage ab RDNA1 / Turing unterstützt.
Ein User hier im Forum hat den Test gemacht, je nach BCn Stufe, kombiniert mit zlib, wurde die Textur bis zu 70% kleiner.
Nvidia spricht von:
https://www.nvidia.com/en-us/geforce/news/rtx-io-gpu-accelerated-storage-technology/
Und Microsoft auch:
Anhang anzeigen 1367669
Also laut diesen beiden erhöht sich die Performance um Faktor 2 durch die komprimierte Übertragung (oder die gesamte Performance? Das geht nicht so ganz daraus hervor).
RDNA1 / Turing vielleicht per Shader, RDNA2 / Ampere dann in Hardware. Werden wir sehen wenn es verfügbar ist.Was nahelegt, dass man mit einer Shader-Implementation arbeitet, denn die Entwicklung dieser Chips muss deutlich vor der von Direct Storage begonnen haben.
Mehr FPS wird es dadurch eher gar keine geben, aber generell schnellere Ladezeiten (ins Spiel rein, Schnellreisen). Immer dann wenn ein kompletter Asset-Austausch stattfindet sollte die Batch-Bearbeitung und komprimierte Übertragung bis zum Endpunkt das Laden beschleunigen.Komprimierung um "bis zu" Faktor 3 laut Userbericht und 1,5-4 in anderen Quellen, die ich gesehen habe, passt gut zu einer Steigerung der Übertragungsgeschwindigkeit um Faktor 2. Eine allgemeine Ansage zur Gesamtperformance für alle Spiele und alle GPUs ist dagegen praktisch unmöglich, das Direct Storage nur einen kleinen Teil der Renderpipeline adressiert und somit je nachdem, wie stark der limitiert, kann sich irgendwas zwischen 0 und 100 Prozent Durchschlag auf die Fps geben.
Das sehe ich anders, wenn Sampler Feedback Streaming die niedrigeren MIP-Level eines Assets on-the-fly nachlädt (und so ist es ja erklärt worden), dann geht es hier nicht ohne Verbesserung der IO Rates. Und genau da setzt ja DirectStorage an, ich wiederhole mich: Reduzierung des CPU Overheads und Batch-Bearbeitung von Asset-Calls.Zum Sampler Feedback: Intelligente Nachladesysteme sind erst einmal unabhängig davon, wie nachgeladen wird. Desweiteren habe ich dazu auch noch keine Beispiele mit realistischen Spiele-Szenen gesehen. Microsofts X-Box-Demo legt nahe, dass es passend zum Namen Feedback vor allem die Eviction nicht benötigter Texturen beschleunigt, was bei exklusiv der GPU zur Verfügung stehendem RAM aber egal wäre.
RDNA1 / Turing vielleicht per Shader, RDNA2 / Ampere dann in Hardware. Werden wir sehen wenn es verfügbar ist.
Mehr FPS wird es dadurch eher gar keine geben, aber generell schnellere Ladezeiten (ins Spiel rein, Schnellreisen). Immer dann wenn ein kompletter Asset-Austausch stattfindet sollte die Batch-Bearbeitung und komprimierte Übertragung bis zum Endpunkt das Laden beschleunigen.
Das sehe ich anders, wenn Sampler Feedback Streaming die niedrigeren MIP-Level eines Assets on-the-fly nachlädt (und so ist es ja erklärt worden), dann geht es hier nicht ohne Verbesserung der IO Rates. Und genau da setzt ja DirectStorage an, ich wiederhole mich: Reduzierung des CPU Overheads und Batch-Bearbeitung von Asset-Calls.
Also ich habe z.B. während ich Division 2 gezockt habe eine NVME in mein System eingebaut, das Schnellreisen hat sich alleine dadurch massiv beschleunigt. Ich denke da kommt es auf die Engine an, beim Schnellreisen könnte ich mir einen "complete VRAM flush" vorstellen. Immerhin weiss die Engine (ohne Sampler Feedback) nicht genau welche Texturen in welchem MIP Level gerade im VRAM liegen.Habe das nie systematisch getestet, aber in den meisten Spielen scheinen mir die Ladezeiten beim Schnellreisen deutlich länger zu sein, als für die Kopie des minimalen/aktiv genutzten VRAM-Inhalts aus dem RAM oder gar von der SSD benötigt werden würde. Das gilt um so mehr als wenn zwischen Gebieten mit ähnlichem Texturset gereist wird. Witcher 3 zum Beispiel benutzt meiner Erinnerung nach maximal 3 GiB VRAM und typischerweise weniger als 2 GiB (ohne Mods), von denen beim Schnellreisen zwischen zwei Punkten in der gleichen Gegend 1,5 GiB identisch zu bestücken sind. Es müssen also weniger als 500 MiB über die 32-GB/s-Verbindung zwischen GPU und CPU transportiert werden, nicht einmal für die Einblendung eines Ladebildschirms reichen würde.
Meine Vermutung: Da werden eher die gesamten anderen Informationen, vor allem die Position diverser Objekte in der Gegend, gespeichert.
Zum Nachladen von Auflösungsstufen: Das wird meinem Wissen nach seit AGP 1.0 unterstützt.
Das ist doch genau der Punkt, wenn die Game-Devs ihr Streaming perfekt optimiert haben dann liegen die passenden Texturen immer dann im RAM wenn sie benötigt werden. SFS optimiert das nun automatisch, immer, ohne Ratespiel.Die Engine weiß nicht, welche Daten noch im VRAM liegen, dass stimmt, weil überschüssiger VRAM vom Treiber selbst in Eigenregie als Cache verwaltet wird. Aber das spielt eben genau deswegen keine Rolle, denn der Treiber ist auch an allen anderen Schritten beteiligt. Die Engine muss nur sagen, was gerendert werden soll – die Daten organisiert sich die GPU dann selbst. (Zumindest solange sie im RAM vorliegen, aber das tun sie auf dem PC eben, wenn der Entwickler keinen Fehler gemacht hat.)
Zum "vorladen" in den RAM/VRAM müssen die Game-Devs aber weiterhin raten, eben weil sie mit alten Streaming-Techniken kein Feedback vom Sampler erhalten und somit wissen könnten was gebraucht wurde. Es geht auch nicht nur um "Wieviel der geladenen Textur ist überhaupt sichtbar?" sondern auch "Wieviel der geladenen Textur ist überhaupt sichtbar und in welchem MIP-Level wird sie benötigt?".Zum Raten sagt dein eigener Link alles:
"Before Sampler Feedback, the developers lack the ability to optimize things to the absolutely last drop. They could only make some guesses about visibility, importance or so".
Die Entwickler mussten nie raten, welche Mip-Stufe sie von welcher Textur brauchen. Im Gegenteil, das gibt es meinem Wissen nach sogar noch die Engine bevor beziehungsweise sie kann zumindest Vorgaben machen, bis zu welcher Empfehlung der Treiber welche Mip-Stufe wählt. Unbekannt ist nur das "letzte" Detail: Wieviel der geladenen Textur ist überhaupt sichtbar?
Soweit ich SFS+DS verstanden habe wird genau das gemacht, Frame 1 wird beispielsweise (wie Du sagtest) mit höherem MIP-Level ausgegeben, SFS streamt die Texturen die in einem niedriger benötigten MIP-Level zu sehen sind nach (also detaillierter) und gibt sie schnellstmöglich mit automatischem Filter zur besseren Überblendung in Frame 2-3-4-usw aus.Aber das weiß auch SFS erst nachdem die Szene gerendert wurde. Dann können mit SFS Texturteile, die im Moment nicht benötigt werden, wieder aus dem VRAM geschmissen werden, aber zunächst wird die volle Kapazität benötigt. Eventuell kann das mal in Kombination mit hohen Fps-Raten und verzögertem Streaming genutzt werden, um die VRAM-Anforderungen allgemein zu senken (man rendert die Szene einmal in Qualität "Matsch", damit man die sichtbaren Texturbereiche kennt, und lädt diese dann in HD nach). Aber im Moment ist der Trend am PC genau das Gegenteil: Es wird VRAM weit über das für das aktuelle Bild benötigte und sogar über der von der Engine gemeldeten Bedarf hinaus mit alten Texturen als Cache gefüllt, um bei der nächsten Bewegung möglichst nichts über den lahmen PCI-E-Slot nachladen zu müssen.
As we have stated, the Sampler knows what it needs. The developer can answer the request of Mip 0 by giving Mip 0.8 on frame 1, Mip 0.4 on frame 2, and eventually Mip 0 on frame 3.