G
gaussmath
Guest
Per CLI benutzbar bleiben.
Dass du aber auch kein Windows hast... Dann geh ich halt über App Argumente oder binde eine Config ein.
Zuletzt bearbeitet von einem Moderator:
Per CLI benutzbar bleiben.
Windows ist heute so wie früher Linux und Linux ist heute so wie früher Windows.Dass du aber auch kein Windows hast...
Wieso nicht? Nach allem was ich bisher verstanden habe wird das mehr und mehr zum Speicherbenchmark je weniger von dem Array in den Cache passt. Dass es dann mit langsamerem Speicher schlechter läuft hätte ich erwartet. Oder bin ich völlig auf dem Holzweg?Das läuft quasi mit dem Faktor 2400/3466 schlechter... Ich kapier's nicht.
Nochmal zu meinem Test der 64MB Variante. Wenn die Daten, wie bei anderen auch, nur zum Teil in den L3 passen, warum greift dann nicht beim Rest mein schneller Speicher?
Ich hätte jetzt gedacht, dass die geringen Latenzen von 10-10-10-24 gewichtiger sind als der hohe RAM Takt, da die Speicherzugriffe ja zufällig verteilt sind.
Wenn ich den Code richtig gelesen habe sind sie das nicht, zumindest nicht wenn man Prefetching berücksichtigt. Die maximale Sprungweite von 255 ist zu klein. Wenn man im gesamten Array zufällig hin- und herspringen würde wären die Latenzen wichtiger als die Bandbreite.
Im Moment sage ich spontan: Durch RAM-Wechsel sind die RAM-Latenz größer, aber fast identisch. Speicherinterface läuft mit reduziertem Clock und diesen Faktor sehen wir.
Weil Deine CPU-Latenzen hoch sind und bei jedem Zugriff zu viele unbenötigte Daten geholt werden.
Genau das ist hier die Frage. Kann man Python-code instrumentieren so dass Cache-misses ausgewertet werden können?Wie viel Prefetch haben wir denn?
Genau das ist hier die Frage. Kann man Python-code instrumentieren so dass Cache-misses ausgewertet werden können?
// Default mit 16MB Array Größe
SC_bench_memcs_Params.exe
// Batch Run mit Potenzen 2^n und n aus { 17, 18, 19, 20, 21, 22, 23, 24, 25, 26 }
SC_bench_memcs_Params.exe -batch
// Single Run mit n aus { ...,17, 18, 19, 20, 21, 22, 23, 24, 25, 26,... }
SC_bench_memcs_Params.exe -exponent n[COLOR=blue]using System;
[COLOR=blue]using System.Diagnostics;
[COLOR=blue]namespace SC_bench_mem
{
[COLOR=blue]internal [COLOR=blue]class [COLOR=#2b91af]Options {
[COLOR=blue]public [COLOR=blue]bool Batch { [COLOR=blue]get; [COLOR=blue]internal [COLOR=blue]set; }
[COLOR=blue]public [COLOR=blue]int TestSize { [COLOR=blue]get; [COLOR=blue]internal [COLOR=blue]set; }
}
[COLOR=blue]internal [COLOR=blue]class [COLOR=#2b91af]CommandLineParser {
[COLOR=blue]internal [COLOR=blue]static [COLOR=blue]bool Parse([COLOR=blue]ref [COLOR=#2b91af]Options options, [COLOR=blue]string[] args)
{
[COLOR=blue]if (args.Length == 0)
{
options = [COLOR=blue]new [COLOR=#2b91af]Options() { Batch = [COLOR=blue]false, TestSize = 24 };
[COLOR=blue]return [COLOR=blue]true;
}
[COLOR=blue]else [COLOR=blue]if (args.Length == 1)
{
[COLOR=blue]if (args[0] != [COLOR=#a31515]"-batch")
{
[COLOR=blue]return [COLOR=blue]false;
}
[COLOR=blue]else {
options = [COLOR=blue]new [COLOR=#2b91af]Options() { Batch = [COLOR=blue]true };
[COLOR=blue]return [COLOR=blue]true;
}
}
[COLOR=blue]else [COLOR=blue]if (args.Length == 2)
{
[COLOR=blue]if (args[0] != [COLOR=#a31515]"-exponent" || ![COLOR=#2b91af]Int32.TryParse(args[1], [COLOR=blue]out [COLOR=blue]int testsize))
{
[COLOR=blue]return [COLOR=blue]false;
}
[COLOR=blue]else {
options = [COLOR=blue]new [COLOR=#2b91af]Options() { Batch = [COLOR=blue]false, TestSize = testsize };
[COLOR=blue]return [COLOR=blue]true;
}
}
[COLOR=blue]else {
[COLOR=blue]return [COLOR=blue]false;
}
}
}
[COLOR=blue]class [COLOR=#2b91af]Program {
[COLOR=blue]private [COLOR=blue]static [COLOR=#2b91af]Random _random;
[COLOR=blue]private [COLOR=blue]static [COLOR=blue]int[] _testSizes = { 17, 18, 19, 20, 21, 22, 23, 24, 25, 26 };
[COLOR=blue]static [COLOR=blue]void Main([COLOR=blue]string[] args)
{
[COLOR=#2b91af]Options options = [COLOR=blue]null;
[COLOR=blue]bool isValidArgs = [COLOR=#2b91af]CommandLineParser.Parse([COLOR=blue]ref options, args);
[COLOR=blue]if (!isValidArgs)
{
[COLOR=#2b91af]Console.WriteLine([COLOR=#a31515]"Error: Invalid app parameter");
[COLOR=#2b91af]Environment.Exit(0);
}
[COLOR=#2b91af]Console.WriteLine([COLOR=#a31515]"Start benchark? Press any key.");
[COLOR=#2b91af]Console.ReadLine();
[COLOR=blue]if (!options.Batch)
{
[COLOR=#2b91af]Console.WriteLine([COLOR=#a31515]"Starting single run...");
[COLOR=blue]double seconds = TestRun(([COLOR=blue]int)[COLOR=#2b91af]Math.Pow(2, options.TestSize));
[COLOR=#2b91af]Console.WriteLine([COLOR=#a31515]"Finished run with testsize {0} int {1} seconds.", ([COLOR=blue]int)[COLOR=#2b91af]Math.Pow(2, options.TestSize), seconds);
}
[COLOR=blue]else {
[COLOR=#2b91af]Console.WriteLine([COLOR=#a31515]"Starting batch run...");
[COLOR=blue]foreach ([COLOR=blue]var testSize [COLOR=blue]in _testSizes)
{
[COLOR=blue]double seconds = TestRun(([COLOR=blue]int)[COLOR=#2b91af]Math.Pow(2, testSize));
[COLOR=#2b91af]Console.WriteLine([COLOR=#a31515]"Finished run with testsize {0} int {1} seconds.", ([COLOR=blue]int)[COLOR=#2b91af]Math.Pow(2, testSize), seconds);
}
}
[COLOR=#2b91af]Console.WriteLine([COLOR=#a31515]"Benchmark completed.");
}
[COLOR=blue]private [COLOR=blue]static [COLOR=blue]double TestRun([COLOR=blue]int testSize)
{
_random = [COLOR=blue]new [COLOR=#2b91af]Random(241500528);
[COLOR=blue]const [COLOR=blue]int cycles = 2048;
[COLOR=blue]byte[] testdata = [COLOR=blue]new [COLOR=blue]byte[testSize];
[COLOR=blue]for ([COLOR=blue]int i = 0; i < testSize; i++)
{
testdata[i] = ([COLOR=blue]byte)_random.Next(1, 255);
}
[COLOR=blue]int the_sum = 0;
[COLOR=#2b91af]Stopwatch stopwatch = [COLOR=blue]new [COLOR=#2b91af]Stopwatch();
stopwatch.Start();
[COLOR=blue]for ([COLOR=blue]int k = 0; k < cycles; k++)
{
[COLOR=blue]int value = k;
[COLOR=blue]while (value < testSize)
{
[COLOR=blue]if (testdata[value] > 128)
{
value += testdata[value];
}
[COLOR=blue]else {
[COLOR=blue]if (value > 0)
value--;
}
}
the_sum += (value % cycles);
}
stopwatch.Stop();
[COLOR=blue]if (the_sum == 0)
{
[COLOR=blue]throw [COLOR=blue]new [COLOR=#2b91af]Exception([COLOR=#a31515]"Error: Wrong test sum");
}
[COLOR=blue]else {
[COLOR=blue]return [COLOR=#2b91af]Math.Round(stopwatch.ElapsedMilliseconds * 1E-03, 3);
}
}
}
}Start benchark? Press any key.
Starting batch run...
Finished run with testsize 131072 int 0,006 seconds.
Finished run with testsize 262144 int 0,015 seconds.
Finished run with testsize 524288 int 0,036 seconds.
Finished run with testsize 1048576 int 0,081 seconds.
Finished run with testsize 2097152 int 0,179 seconds.
Finished run with testsize 4194304 int 0,383 seconds.
Finished run with testsize 8388608 int 0,888 seconds.
Finished run with testsize 16777216 int 2,569 seconds.
Finished run with testsize 33554432 int 5,065 seconds.
Finished run with testsize 67108864 int 10,356 seconds.
Benchmark completed.Pinning kann ich u.a. per CLI machen. Bisher hatte das kaum/nichts etwas gebracht.Ich habe das Programm umgebaut, so dass von außen Parameter übergeben werden können. Core Pinning konnte ich leider nicht so integrieren, dass es mit Linux kompatibel ist, weil das über Sys-Calls läuft unter C#.
Interessant ist, dass die Laufzeiten immer ziemlich proportional zu Array Größe sind. Ich hätte gedacht, dass es zu Sprüngen kommt, wenn die Daten nicht mehr in den L3 passen.
Genau das ist hier die Frage. Kann man Python-code instrumentieren so dass Cache-misses ausgewertet werden können?
Den Ergebnissen zu Folge haben wir ein besseres Prefetching als nur die nächste cache-line. Eventuell mal den Hardware-Prefetcher im Bios abstellen und schauen was passiert.
Die Annahme dass immer nur die nächste cache-line geladen wird ist jedenfalls zu kurz gesprungen.
Pinning kann ich u.a. per CLI machen. Bisher hatte das kaum/nichts etwas gebracht.
Mit dem Code habe ich Probleme (u.a. "declaration exression", C# 6.0 (line 76, dann irgendwas in 73...)
Bezüglich eines Dies zeigen Deine Werte auch genau das. Insofern genau passend zu Deiner Annahme.
Es ist halt schade, dass wir den Cache vom anderen Die nicht nutzen können. Vielleicht will AMD das nicht, weil man sich auch ohne dies bereits um die Bandbreite zwischen den Dies sorgt?
") Mein Xeon stinkt ziemlich ab gegen den Theadripper:
Mein Xeon stinkt ziemlich ab gegen den Theadripper:Start benchark? Press any key.
Starting batch run...
Finished run with testsize 131072 int 0.035 seconds.
Finished run with testsize 262144 int 0.054 seconds.
Finished run with testsize 524288 int 0.085 seconds.
Finished run with testsize 1048576 int 0.312 seconds.
Finished run with testsize 2097152 int 0.32 seconds.
Finished run with testsize 4194304 int 0.83 seconds.
Finished run with testsize 8388608 int 1.466 seconds.
Finished run with testsize 16777216 int 5.121 seconds.
Finished run with testsize 33554432 int 10.614 seconds.
Finished run with testsize 67108864 int 22.757 seconds.
Benchmark completed.Du sollst Python ab Version 3.5 nehmen. Steht im Eingangspost, im Sourcecode und im Dateiname.
Ich arbeite sonst ja auch mit dem 2er. Aber gab bereits Leute, die nur das 3er installiert haben. Deshalb habe ich eine 3er Version gemacht. Durchläufe mit 2er und 3er sind nicht vergleichbar. Für das eine Script kann mal man schon mal das 3er starten")

Wie versprochen. Die Werte von meinem 2700x mit PC3533.Am besten die Exe über cmd starten und den Parameter -batch verwenden. Das ganze 3-5 mal durchlauf lassen...
Starting batch run...
Finished run with testsize 131072 int 0,006 seconds.
Finished run with testsize 262144 int 0,014 seconds.
Finished run with testsize 524288 int 0,034 seconds.
Finished run with testsize 1048576 int 0,076 seconds.
Finished run with testsize 2097152 int 0,169 seconds.
Finished run with testsize 4194304 int 0,362 seconds.
Finished run with testsize 8388608 int 0,815 seconds.
Finished run with testsize 16777216 int 1,916 seconds.
Finished run with testsize 33554432 int 3,931 seconds.
Finished run with testsize 67108864 int 7,759 seconds.
Benchmark completed.Könntest Du bitte auch das python3 Script ein paar mal ausführen (siehe erster Post dieses Threads)?Wie versprochen. Die Werte von meinem 2700x mit PC3533.
Wie versprochen. Die Werte von meinem 2700x mit PC3533.
Starting batch run...
Finished run with testsize 131072 int 0,009 seconds.
Finished run with testsize 262144 int 0,02 seconds.
Finished run with testsize 524288 int 0,047 seconds.
Finished run with testsize 1048576 int 0,105 seconds.
Finished run with testsize 2097152 int 0,226 seconds.
Finished run with testsize 4194304 int 0,483 seconds.
Finished run with testsize 8388608 int 1,141 seconds.
Finished run with testsize 16777216 int 2,75 seconds.
Finished run with testsize 33554432 int 5,554 seconds.
Finished run with testsize 67108864 int 11,261 seconds.
Benchmark completed.Könntest Du bitte auch das python3 Script ein paar mal ausführen (siehe erster Post dieses Threads)?
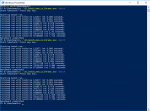
PS D:\python> .\python.exe D:\Benchmarks\SC_bench_memPy3x.py
Generate test data of size 16777216
Checking, if test data is correct
Running the test
Runtime in seconds: 50.530439138412476
PS D:\python> .\python.exe D:\Benchmarks\SC_bench_memPy3x.py
Generate test data of size 16777216
Checking, if test data is correct
Running the test
Runtime in seconds: 50.656702756881714
PS D:\python>Ja Timings sind optimiert siehe http://extreme.pcgameshardware.de/attachments/1003306d1531991066-sammelthread-amd-ryzen-3533.pngVielen Dank! Der 2700X schlägt sich wirklich ziemlich gut. Besser sogar als ich dachte. Hast du auch die Subtimings optimiert?
{kind=link}