aber passt die nicht auch auf den Sockel 7
Boah geil, das Ding kann 2,8V Kernspannung liefern, damit werde ich wohl die 10Ghz erreichen
.gif "sm_B-) :-)")
Nicht zu vergessen, die Ultra 9 brauchen den Super-Socket 7
Die Fertigung der CPU ist deutlich fortschrittlicher als bei Raptor Lake, das sind "klassische" Verbesserungen
Also bei 165W weniger Verbrauch tue ich mich auch schwer damit, denn das ist in etwa der Gesamtverbrauch eines 14900K gewesen im Gaming (im Durchschnitt aller Games liegt dieser ja sogar deutlich drunter).
Der Node Shrink ist ein vorteil für den Stromverbrauch ja.
Das haben wir immer alle gedacht, die jüngere Vergangenheit zeigt aber nicht wirklich genau dieses Bild. Denn scheinbar werden bei Nodes immer nur die Leistungsvorteile mitgenommen und die Effizienz und der Verbrauch außen vor gelassen. Schau mal in die Effizienztabellen bei PCGH, ein 8700k liegt bspw. vor den aktuellen Gens und das sogar sehr sehr deutlich (rein auf das Gaming bezogen)
Node Shrinks sind meistens geil aber bei 5090 wirds wohl etwas enttäuschen
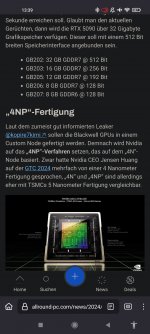
Ist ein Node Shrink angekündigt? Soweit ich weiß soll es in N4P gefertigt werden, also dem gleichen Node wie der Vorgänger. Meine nur, dass es dort N4 war und nicht N4P; was aber eben marginale Unterschiede sind, beide Prozesse gehören ja sogar dem N5 Prozess an.
Nicht wirklich. Sonst wäre nicht der 7800X3D der aktuelle King of the Hill sondern der 7950X3D mit 'ner zusätzlichen Kachen mit 8 Kernen.
Schwierig. Denn Tiles / MCM sind der einzig gangbare Weg! Glaube auch, dass AMD hier auf dem richtigen Weg ist. Aber Monolithen sind erst einmal nahezu immer besser als vergleichbare Tiles/MCM Designs, eben auf Grund der Latenzproblematiken. Das Thema ist aber nicht so simpel, denn der Core Count wächst und Monolithen werden hier vor unlösbare Fertigungsprobleme gestellt, die Tiles/MCM eben nicht hat.
Also subjektives Fazit ist für mich; Tiles sind die Zukunft, auch wenn Monolithen eigentlich besser sind.
Diese Zerstückelung in Kacheln ist und bleibt eine technologisch-finanzielle Notlösung,
Ich würde es nicht unbedingt Notlösung nennen, da es eben Millionen von Anwendungen gibt, die InterCore Latenzen nahezu nicht oder wirklich gar nicht interessieren. Das sind dann eben auch meist die Anwendungen die gut parallelisierbar sind. Für die anderen Anwendungen (im speziellen Gaming) sind 8 Kerne immer noch gut genug und daher sehe ich keine Notlösung, sondern eher einen konstruktiv und technologisch bedingten Kompromiss in dem Design, der offensichtlich gut genugt funkioniert.
Und würde AMD das CCD mit dem IO-Die zu einen Die verschmelzen, war da noch wesentlich mehr drin. Nur geht dann der Yield gewaltig runter, da Chipfläche hoch geht.
Nicht zu vergessen, dass der IO Die in einem älteren ProzessNode gerfertigt wird und daher die Fläche schon wesentlich günstiger ist als in einem aktuellen N4/N3.
Windows ist einfach ein riesen Problem. Mit ihrem ganzen Prefetching nonesense hätten sie schon längst die ingame leistung messen können und die game exe den optimalen cores zuweisen können.
Naja, da muss man dann aber eben auch sagen, dass Intel das besser löst!
Wenn der 9950x3d wirklich auf allen tiles denselben cache hat, wird das das problem beheben, aber unnötig teuer weil M$ seine Arbeit nicht vernünftig macht.
Mal abwarten, denn ob das wirklich was bringt? Wenn dann nur in Spielen mit mehr als 8 Kernen und dann eben auch nur wenn der Scheduler das ordenlich mitmacht. Bin aktuell noch kein Freund davon und hoffe eher auf Zen 6 mit 16 Kernen je CCD und dann eben 3D Cache auf 16 Kernen.
Ich dachte diese verwirrtaktik mit falschen nm angaben macht nur Intel xD
Naja Intel hat da irgendwann nachgezogen, wer angefangen hat mag ich nicht zu beurteilen. Aber schon seit langer Zeit sind die Prozessnamen nicht mehr in Einklang zur Fertigung zu bringen. TSMCs 14nm Prozess bspw. war dem Intelschen 14nm Prozess massiv unterlegen, die Lücke konnte man erst mit 10nm schließen und erst mit 7nm gegen 14nm war man dann leicht vorne. Daher hat Intel den hauseigenen 10nm Prozess dann schnell in Intel 7 umbenannt um eben mit TSMCs N7 zu konkurrieren; heuer nennt Intel seinen Prozess Intel 3 um damit markentechnisch mit TSMCs N3 zu konkurrieren, obwohl erst Intel 18A die Lücke wird schließen können, selbst Intel 20A (Intel 2)scheint nicht auf dem Level von N3 zu liegen.
Also da tragen die beiden wichtigen Hersteller schon gut zu bei, das die Namen hier Schall und Rauch sind.
Nachdem also TSMC, GloFo, Samsung usw. angefangen haben ihre zahlen ziemlich willkürlich zu verkleinern hat Intel irgendwann gesagt ok wir müssen da mitmachen um nicht blöd auszusehen
Hatte aber wahrscheinlich auch eher etwas damit zu tun, dass man sich ziemlich der Lächerlichkeit preisgegeben hat, nachdem man hunderte Pluszeichen an das 14nm Verfahren gehängt hat. Dazu eben technisch abgehängt wurde und somit das Marketing einen wichtigeren Stellenwert bekam, denn man lag nicht mehr vorne.
Wäre man heuer mit dem eigentlichen geplanten 2nm unterwegs (10nm in 2015, 7nm in 2017 (originale Roadmap aus 2013); demzufolge 5nm in 2019, 3nm in 2021, 2nm in 2023 und 1nm in 2025) , und TSMC mit N3, würde der Name niemanden interessieren (selbst wenn TSMC seinen Prozess N0,1 nennen würde); denn man würde weit weit vor der Konkurenz liegen.
")