@RX480: Ob die "
minFps ausreichend" sind oder nicht ist eine rein subjekte Betrachtung und liegt damit außerhalb meiner Betrachtung. Fakt ist, dass wenn man die Leistungskurven und Auflösungsskalierungen der beiden GPU-Serien gegenüberstellt, RDNA2 relativ gesehen in 4k stärker abfällt als Ampere, was schlicht an dem L3 liegt **), der aus Gründen der Wirtschaftlichkeit nur eine beschränkte Größe auf dem Die haben darf (
Wafer-Kosten) und bei 4K in Relation gesetzt so klein wird, dass die Leistungseinbußen größer ausfallen. Das sind keine "Welten" *) , aber die Unterschiede sind deutlich zu sehen und klar auf den L3 und die deutlich steigende Zahl an Cache Misses zurückzuführen (
wie es auch AMD selbst erklärt). Für 4K ist offensichtlich eine RTX 3090 oder bald eine RTX 3080 Ti die bessere Wahl i. V. z. einer RX 6900 XT (
auch bereits ohne die bessere Raytracing-Performance oder DLSS; was aber selbstredend keinen daran hindern muss mit bspw. seiner RX 6900 XT glücklich zu sein, denn die ist dennoch eine gute Karte).
*) Wobei natürlich auch das subjektiv ist. Im PCGH-Test mit 20 Titeln ist die RX 6900 XT i. V. z. RTX 3090 quasi durchgehend langsamer, in acht Titeln gar um >= 20 % langsamer und bereits bei zwei weiteren Titel > 18 % langsamer. Der Mittelwert über alle 20 Titel liegt bei 17,1 % langsamer als die RTX 3090 in 4K mit Max-Settings.
Ergänzend: In 1440p ändert sich das Bild jedoch nicht übermäßig. Der Mittelwert verringert sich nur auf 13,5 % langsamer als die RTX 3090. Erst mit aktiviertem SAM kann die Karte hier signifikant besser abschneiden bei den 20 Titeln, bleibt aber dennoch gemittelt 9,9 % langsamer als die RTX 3090 in 1440p bei Max-Details bei der PCGH. Aktiviert man auch auf der Ampere-Karte ResBAR; wird der Abstand wieder ein wenig größer.
(
Ein deutlich besseres Bild in 1440p zeigt sich (ohen SAM) erst im Vergleich zur RTX 3080. Hier ist die RX 6900 XT im Mittel über alle 20 Titel nur noch 3,4 % langsamer als die RTX 3080.)
**) Natürlich in Kombination mit dem deutlich langsameren GDDR6.
***) Ergänzend zu FP16: Der Vergleich ist unzutreffend. RNDA2 hat bzgl. FP16 keinen architektonischen Vorteil ggü. Ampere.
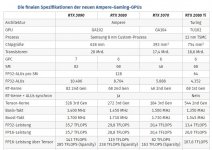
RX 6900 XT: 46,1 TFlops
RTX 3090 FE: 35,7 TFlops
Der Unterschied ist im höheren Takt der RDNA2-GPU begründet, der Durchsatz ist in beiden Architekturen gleich. Bei Ampere schreibt man aktuell lediglich "1x", da man die zusätzliche FP32-Einheit nicht auf eine FP16-Prozessierung erweitert hat.
Darüber hinaus ist das bei Ampere auch lediglich die FP16-Leistung exklusive der Tensor Cores; mit diesen ist die FP16-Leistung gar noch um ein Vielfaches höher.
@Nathenhale: "
Ampere Integer-Nachteile"? Rein architektonisch hat Ampere diesbezüglich grunsätzlich keinen Nachteil, eher gar einen Vorteil, denn Ampere kann hier gar eine INT-Op und eine FP-Op parallel ausführen, was RDNA2 nicht kann. Und bezüglich des reinen INT-Durchsatzes der ALUs dürften beide Designs in etwa vergleichbar schnell sein.
Was jedoch einen Unterschied ausmachen wird, ist der deutlich höhere Takt bei RDNA2, d. h. dieses kann tendenziell schon etwas mehr INT-Ops prozessieren, kommt aber bei FP-Ops nicht mit, da Ampere hier gar zwei Operationen parallel prozessieren kann.
Was jedoch schwer fällt, ist die Relevanz diesbezüglich auch schlüssig zu belegen. Es zeigen sich zwar eindeutige Unterschiede zwischen einzelnen Engines und gar auch nur in bestimmten Titel, jedoch bleibt die Frage hier unbeantwortet, ob bessere Ergebnisse bei RDNA2 hier speziell auf diesen "
Integer-Vorteil" oder eher allgemein auf eine grundlegend bessere Engine-Optimierung für die RDNA-Architektur zurückzuführen sind?
*) Ergänzend bleibt zu berücksichtigen, dass die Relevanz an INT-Ops grundsätzlöich in jeder GameEngine kleiner ist als die von FP-Ops, d. h. der deutliche Taktunterschied führt nicht zu einer äquivalent höheren, relevanten INT-Performance. Der Anteil der INT-Operationen schwankt von Engine zu Engine und selbst zwischen Titeln auf einer Engine und liegt bei etwa 15 % bis voraussichtlich bestenfalls 33 % INT-Ops (anteilig).

")
 Tja, so läuft das nicht...
Tja, so läuft das nicht...") Deswegen limitiere ich die fps ja auch auf den Wert, wo's mir "reicht". Ob ich 150, oder 850 fps maximal hab is mir wurscht, da ich aktuell immer auf 70 fps limitiere, da ich das ganz angenehm empfinde zum Zocken und nicht (nutzlos) zu viel Strom verpulvere.
Deswegen limitiere ich die fps ja auch auf den Wert, wo's mir "reicht". Ob ich 150, oder 850 fps maximal hab is mir wurscht, da ich aktuell immer auf 70 fps limitiere, da ich das ganz angenehm empfinde zum Zocken und nicht (nutzlos) zu viel Strom verpulvere.