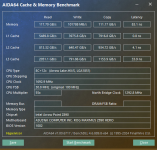
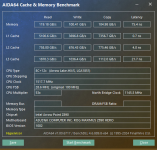
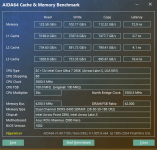
"Quasi monolithic" habe ich bei Intel seit Sapphire Rapids nicht mehr gehört. Da wurde für die EMIB-Verbindung 2,4 ns bei vollem Fabric-Clock versprochen – im Vergleich zu meinem Wissen nach 1-3 Zyklen pro Hop, also 0,6 ns bis 1,8 ns bei 1,6 GHz Uncore, im normalen Mesh wirklich wenig. (Weiß aber nicht mehr, ob @PCGH_Daves Messwerte diese Größenordnung bestätigen.)
Bei MTL oder ARL war davon nichts mehr zu hören und da zumindest dem Namen nach, aber zumindest im Falle von MTL auch dem Power Management zu Folge, auf dem SoC-Tile ein anderes Verbindungssystem als auf dem Compute-Tile genutzt wird, kann das T2T-Interface nicht mehr eine einfache Befehlsdurchleitung sein, sondern muss Abstrahierungsschichten dazwischen haben. Trotz allem war aufgrund der physisch viel besseren Verbindungseigenschaften eines Si-Interposers eigentlich ein weitaus besserer Wert zu erwarten als bei Chiplet-CPUs. Was stattdessen real geboten wird...