Ich sehe bei NV keine besondere Hardwareunterstützung für DP4a.(x)
Tensor ist very special und ohne Anpassung geht Da wohl eher erstmal NIX.
(x) wenns wie bei FP16+INT8 läuft, könnte Turing evtl. ganz gut damit
Die Ausage ist unzutreffend,.
nVidia unterstützt DP4A bereits seit Pascal. Konkret unterstütrzt man hier sogar noch zwei zusätzliche Varianten DP2A(hi) und DP2A(lo) die jedoch mit INT16 als Eingabewerten arbeiten.
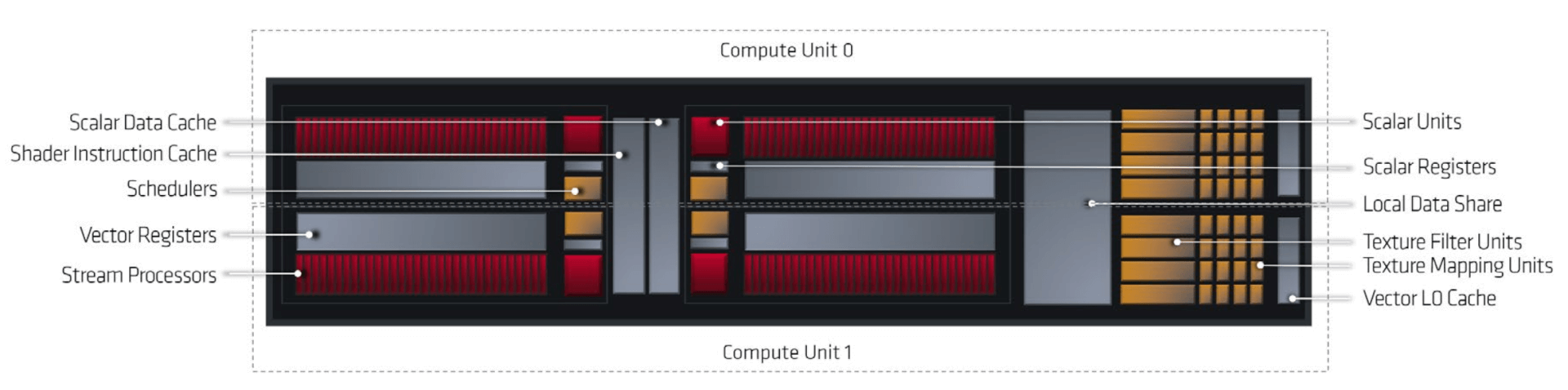
Wesentlicher ist jedoch, dass bereits die Tensor Cores v2 von Turing vollumfänglichen Support für INT8/FP32 und INT4/FP32 bieten, d. h. die sind dafür grundsätzlich am besten aufgestellt, denn während die Implementation bei Intel und auch die Funktionalität bei AMD nur zusätzliche "Verdrahtung" und Datenpfade in den ALUs bedeutet, handelt es sich bei nVidia um dedizierte HW-Einheiten.
AMD spricht nicht groß über ihre Mixed Precision-Leistung, weil RDNA nicht darauf abzielt und man im direkten Vergleich gegen nVidia grundsätzlich deutlich den Kürzeren zieht. Darf man den Infos auf
When AMD announced its Radeon RX 6800 series and 6900 XT GPUs, otherwise known as Big Navi last month, the architectural details were quite sparse. There were two features that were the primary focus: The huge 128MB of L3 cache, dubbed as the Infinity Cache by AMD, and the relatively high core...

www.hardwaretimes.com
Glauben, erreicht RDNA2 aber dennoch Mixed Precision INT8/INT32 512 Ops/Cycle/CU, was in etwa auf dem Niveau des Durchsatzes von Intels Xe liegt. *)
Unterm Strich hat man hier also eine weitere Technik, die auf sämtlichen, halbwegs aktuellen Architekturen laufen wird, auf Intel- und AMD-Hardware in etwa vergleichbar schnell und nVidia's Hardware hat aufgrund der Tensor Cores v3 hier einen deutlichen Vorteil bzgl. des Inferencing-Teils des Workloads, wenn man diese den nutzen wird. **)
*) Die beiden größten RDNA2-Modelle sind absehbar gar geringfügig leistungsfähiger aufgrund mehr CUs und ein wenig mehr Takt, denn aktuell vermutet man, dass Intels Design sich bei grob um die 2 GHz bewegen wird und deren vorläufiges Topmodell wird sich auf 512 EUs beschränken (64 Ops/Cycle/EU in Xe-LP).
**) Eine RX 6800 XT erreicht, je nachdem welchen Takt man anrechnet zwischen 74,5 - 83,0 TOPS INT8, eine RTX 3080 erreicht mit ihren Tensor Cores v3 dagegen 238 TOPS, also gut den dreifachen Durchsatz. (Und die Implementation auf dem A100 ist nochmals doppelt so durchsatzstark.)
Wenn man Intel's Folie glauben möchte, dann ist der Overhead (falls die Qualität die selbe ist) bei der Berechnung von DP4a über die ALUs nur ein wenig langsamer, als über die Matrix-Einheiten.
Entsprechend wäre es nicht der Hardware geschuldet, dass AMD z.B. nicht auf einen AI-basierten Ansatz setzt, sondern schlicht eine Zeit/Umsetzungsfrage auf Seiten der Software.
In ein paar Monaten kann man das hoffentlich auf Intel's Hardware testen und schauen, ob das tatsächlich so ist.
Die Technik muss ja zwangsweise in absolutem Rahmen einen geringen Overhead haben *), denn andernfalls könnte man ja keine Beschleunigung erreichen.
")
Ich sprach auch nirgends von absoluten Zugewinnen oder habe etwa impliziert, dass Intels HW in einem Vergleichbaren Setup 2,0x Fps erreicht, während die Technik auf RDNA2 möglicherweise nur 1,2x imstande zu leisten wäre. So deutlich können die Unterschiede natürlicherweise nicht ausfallen.
Darüber hinaus ist ja auch immer noch zu berücksichtigen, wie groß der Inferencing-Anteil an dem Workload insgesamt ist. Je größer der ist, desto bedeutender wird die Mixed Precision-Leistung der Architektur, und entsprechend hat nVidia hier einen potentiellen Vorteil, d. h. wenn sich wer die Mühe macht, das auf die Tensor Cores umzulegen.
nVidia selbst könnte das machen, die Frage ist aber, ob sie ein Interesse daran haben, denn am Ende könnte man dem eigenen DLSS damit das Wasser abgraben. Hier wird man einfach abwarten müssen. **)
*) Wenn ich das recht in Erinnerung habe, dann hatte man in Demonstrationen rund um DLSS exemplarisch etwa um die 16 ms pro Frame gezeigt und davon entfiel irgendwas in der Größenordnung von etwa 1,5 ms auf den DLSS-Pass. Zudem zu beachten ist hierbei der nur halb so hohe Durchsatz, da nVidia mit FP16 bei DLSS arbeitet und nicht mit INT8.
**) Wenn die Eingabeparameter und Anforderungen an die Engine bzgl. Bewegungsvektoren recht ähnlich wären, könnte es gar sein, dass DLSS und XeSS gar weitestgehend austauschbar wären? Noch mehr Spekulatius.
Am Ende muss man aber erst mal abwarten, was die Technik zu leisten vermag und wie konkret sie Intel zu positionieren gedenkt. FSR bringt als General Purpose Lösung schon einen deutlichen Mehrwert, was XeSS da mögicherweise noch draufzulegen vermag ... man wird sehen. Zumindest scheint man guter Dinge zu sein, dass man mehr bieten kann, den andernfalls wäre es ein no-brainer XeSS zu bringen, wenn dieses gar schlechter als das selbst auf Intel-Hardware nutzbare FSR abschneiden würde.
 Zurück zum Artikel: Open-Source-DLSS von Intel: XeSS in Aktion, alle Informationen
Zurück zum Artikel: Open-Source-DLSS von Intel: XeSS in Aktion, alle Informationen