Wer sagt denn was von Speicherüberläufe wegpuffern? Das ist doch gar nicht Sinn und Zweck.
Es geht darum, die CPU Last drastisch zu senken, indem man das Dekomprimieren der Assets für die GPU nicht mehr auf der CPU durchführt. Das ermöglicht es zudem die Datenraten massiv zu erhöhen, weil die GPU halt viel schneller ist.
Wenn es nur darum ginge, dann wäre es auf bestehenden Systemen erst recht sinnlos. Denn ein Großteil der CPU-Ressourcen gängiger Modelle langweilt sich die meiste Zeit, die ein Spiel läuft, zu Tode. Guck dir mal an, welchen Ernergieumsatz reines Dekodieren tatsächlich erreichen kann (z.B. 7zip) und mit was deine CPU beim Zocken im Schnitt rumidlet. Performance-Einbußen auf der CPU durch Entpacken spielen im realen Spielgeschehen nur eine Rolle, wenn viele Assets binnen kurzer Zeit plötzlich bereitgestellt werden sollen. Genau das kann man durch voraussschauendes Streaming vermeiden – oder man entwickelt extra eine Technik, die einen speziellen Co-Prozessor in der GPU erfordert und lässt ohnehin rumliegendes Silizium weiterhin ungenutzt. Mit letzterem kann man als Hardware-Verkäufer natürlich leichter Geld verdienen als ein Software-Entwickler mit einem Spiel, das "just works".
Ich glaube das was du meinst ist die Vorstellung, dass man den Grafikspeicher durch Direct Storage besser ausnutzen kann und Agressiveres Streaming betreiben kann, weil weniger Daten im VRAM vorgehalten werden müssen, weil man neue Daten schneller nachschieben kann. Das wird sicherlich noch kommen und mit Sampler Feedback Streaming vielfach effizienter, da man so zusätzlich den VRAM Footprint der Assets minimieren kann, aber auch das soll doch nicht dafür sorgen, dass ein vollaufen des VRAMs kompensiert werden soll.
Wenn nur 8 GB vorhanden sind und 10 GB gebraucht werden, wird es mit Direct Storage genauso ruckeln wie bisher auch.
Der Unterschied wird sein, dass man mit reduzierten Settings, welche in 8 GB platz finden deutlich bessere Grafik qualität erzielen wird, eben dank Sampler Feedback Streaming, Virtual textures und allgemein agressiveres Streaming.
Damit letzteres möglich ist und die CPU damit nicht ständig genervt wird, hilft hier eben Direct Storage mit GPU Dekomprimierung.
Letztendlich kann man also aus vorhandenen Systemen mittlefristig mehr herausholen, da die Effizienz des Speichermanagements erhöht wird. Die Symptome bei Speichermangel werden aber identisch bleiben.
Aber das ist alles noch ziemlich weit weg und beschreibt nur das Potenzial das hier besteht. Zuerstmal soll Direct Storage das CPU Bottleneck beim Streaming von Assets beheben. Denn das wird in immer mehr Spielen jetzt schon zum Problem, selbst bei noch vergleichsweise geringer Streaminglast. Der aktuelle Ansatz ist einfach veraltet und ineffizient und wird den künftigen Anforderungen nicht mehr gerecht.
"Sampler Feedback" als Schlagwort ist zwar mit Direct Storage assoziiert, aber die Grundidee "lade nur die benötigten Teile eines Assets" wurde spätestens mit Ids Megatexturing etabliert. So etwas einfach nur effizienter und feiner zu gestalten, wäre nicht weltbewegend. Das Versprechen der Entwickler ist es tatsächlich, Daten so schnell "on demand" zu streamen, dass sie nicht mehr im RAM vorrätig gehalten werden müssen. Erst und nur dadurch ergibt sich die Möglichkeit zu komplexeren Assets und einer schöneren Welt respektive zu einem flüssigeren Spielablauf mit einer solchen. Denn wenn ich ohnehin nur mit dem rendere, was schon seit ein paar Sekunden im VRAM bereit liegt, dann spielen (CPU-)Decoding & Co halt gar keine Rolle mehr – intelligentes Prefetching, siehe oben.
Um das Versprechen einzulösen braucht man aber eben nicht nur Direct-Storage-Software und zusätzliche Direct-Storage-Recheneinheiten in der GPU (entpacken über Shader wäre im weit verbreiteten GPU-Limit sogar negativ), sondern auch Hardware die ein passendes Problemszenario bietet: Relativ niedrige GPU-Leistung, ausreichend großer VRAM für komplexe Szenen, aber zu kleiner für komplexe Level, keinen Platz in weiteren Zwischenspeicherstufen (z.B. RAM), um die Level dort zwischenzuspeichern sowie relativ zum Datendurchsatz der GPU (respektive zur Anbindung des RAMs, falls vorhanden) sehr schnelle Laufwerke. Genau das bieten die aktuellen Konsolen, weil sie extra um dieses Paradigma herum konstruiert wurden: Gar kein extra RAM, sehr schnelle SSDs und überschaubare Qualitätsanforderungen an die Grafik, weil die Shader-Leistung eh limitiert.
Aber am PC haben wir genau die gegenteilige Situation: Die Laufwerke sind oft der älteste und lahmste Teil eines sich entwickelnden Builds, zusätzlich zu "bitte mehr als 8" GiB-weise VRAM sind mittlerweile 32 GiB RAM mit Trend zu 64 GiB verbreitet, deren Anbindung an unbeschnittene GPUs ist weitaus schneller als jedes Laufwerk (PCI-E 5.0 wäre zusätzlich verfügbar, wenn man es denn brauchen würde) und die GPUs sollen ein vielfaches der Bildqualität und Datenmenge verarbeiten, die auf Konsolen üblich ist. Da kommt eine SSD sowieso nicht hinterher, egal ob direkt oder indirekt, da muss man den RAM nutzen. Und wenn man das vernünftig macht, ist die (CPU-)Dekomprimierung ausreichend.
Das würde bedeuten dass man alle Assets des Spiels (Texturen, Geometrie, zu kompilierende Shader) in den RAM laden müsste. Wir sprechen hier von 80+ GB bei manchen Titeln. Wer hat so viel RAM? Und wieso sollte man so viel RAM verbauen wenn man effizienter streamen kann?
"Rechtzeitig streamen" in Deiner Formulierung würde bedeuten dass man wieder CPU Cycles benötigt zum Übertragen und Dekomprimieren, womit die GPU wieder auf Assets warten muss bis die CPU fertig ist.
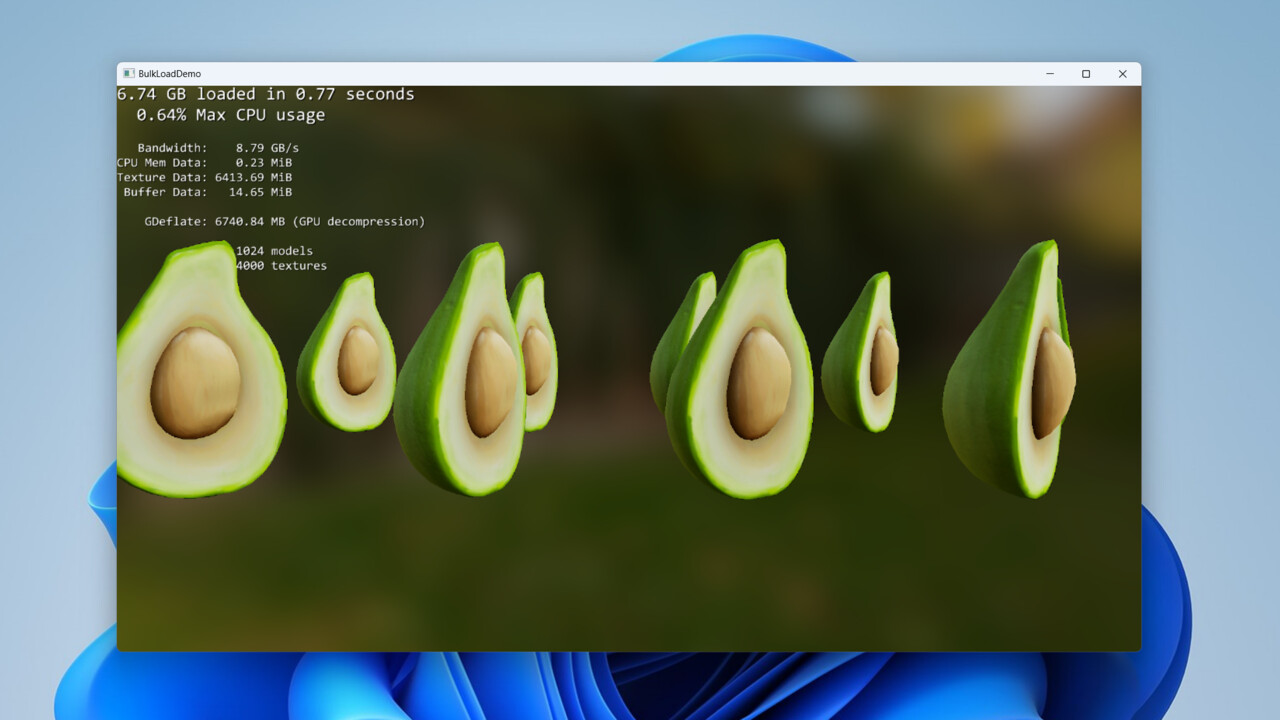
Mach doch einfach mal den Avocado Test und schau Dir den Unterschied lokal auf Deinem System an. In der Demo wird bei CPU Decompression anscheinend keine Rücksicht auf andere Threads genommen, mein ganzes System hing 1-2 Sekunden bis die CPU fertig war.
Mit GPU Decompression habe ich den Ladevorgang gar nicht mitbekommen, er war innerhalb von 480ms erledigt (CPU 2420ms) und hat die Daten mit einer Bandbreite von knapp 12GB/s (was wohl meiner NVME PCIE3.0 Schnittstelle x Komprimierung entspricht) gestreamed, während die CPU knapp 2,3GB/s hinbekommen hat.
Deine "Problemlösung" verschiebt das Bottleneck nur zeitlich anstatt es nachhaltig zu lösen.
Wie oben beschrieben: Saubere Programmierung und intelligentes Streaming umgehen den vermeintlichen Flaschenhals komplett, weil dieser überhaupt nur zeitlich existiert. Klar kann man Tests programmieren, die massiv sinnlose Dekompressionslast auf die CPU packt und diese damit auslastet. Da brauche ich keine Avocado zu, da kann ich 7-Zip-Benchmarks von anno dazumal nehmen. Reale Spiele beweisen dagegen schon seit langem, dass jede 08/15-CPU weitaus mehr Daten schnell genug für die GPU bereitstellen kann, um ansehnlichere Grafik als dieses Gemüse zu produzieren.
Real limitiert die CPU erst hart, wenn über die Laufzeit eines Spiels von der GPU im Schnitt mehr neue Daten verarbeitet werden, als die CPU im Schnitt bereitstellen könnte. Alles andere als "im Schnitt" ist ein Problem, dass sich sowohl im kritischen Moment selbst durch schiere Rohleistung lösen ließe als auch durch eine Dehnung dieses Moments zu einem unkritischen Zeitraum – durch intelligentes Prefetching und Zwischenspeicherung. Deine CPU schafft "nur" 2,3 GB/s an Assets zu verarbeiten? Dann reicht sie für jedes Spiel, in dem 360°-Drehungen mit einer RTX4060 überhaupt möglich sind, ohne dass es abstürzt, und in dem du selbst bei deinen Speedruns mehr als knapp 4 Sekunden von einem Level, Tile, etc. in den nächsten komplett anderen Raum brauchst, in dem du diese 360°-Drehungen machen möchtest.
In realen Spielen kommen solche Sprünge aber fast nur an Portalen vor, deren Annäherung für deutlich mehr als vier Sekunden vorhersehbar ist. Phils Lieblingsbeispiel ist immer der Besenflug von Hogwarts nach Hogsmeade mit massivem Ruckler bei erreichen letzterem. Da wird zwar auch bei weitem nicht alles ausgetauscht, weil zum Beispiel Boden- und allgemein Materialtexturen gleich bleiben, aber sicherlich 50 Prozent oder mehr des Renderinhalts sind neu. Der Flug dauert allerdings 10-20 Sekunden und das Ziel des Spielers ist bereits bei der Richtungswahl kurz nach dem Abheben klar absehbar, zumal es eh keine andere Destination vergleichbarer Komplexität gäbe. Ziehen wir mal 50 Prozent CPU-Leistung für parallel laufende Spielprozesse ab, dann könnte die oben genannte 2,3 GB/s CPU in dieser Zeit also rund 20 GB an neuen Assets entpacken und wenn die 50 Prozent Recyclingquote alter Inhalte richtig geschätzt ist, reicht das für 40 GiB Renderinhalte. So viel dürfte eine aufpolierte, intelligente Version des Spiels verwenden, ehe deine CPU Nachladeprobleme bekäme. Aber was sagt wohl deine GPU zu einer Szene mit so vielen Details, dass 40 GiB VRAM belegt sind?
Eben. Real sind die Grafikkarten der meisten Spieler schon bei 10 GiB am Ende. Die Qualität des Spiels ist also durch komplett andere Faktoren auf ein Viertel der (halben) CPU-Leistung begrenzt. Da kann man sich natürlich überlegen, wie man das ändern kann. Aber es tatsächlich zu machen ist in etwa so hilfreich wie ein Upgrade von einem 1800X auf einen 7800X3D in einem System mit einer GTX 970.
Die Sache ist doch um einiges schwerwiegender als dargestellt. Mit Sampler Feddback Streaming brauchst Du auflösungsabhängig nurmerhr einen festen Speicherpool (VRAM), also nur das "active working set" auf Texelbasis.
Der VRAM ist also nurmehr in Framebuffer und vielleicht noch ein kleiner Streaming- Buffer.
VRAM in der jetzigen Form wäre überflüssig. Um ein 4K Bild mit 16K vollgekleisterten Texturen auf den Bildschirm darzustellen, wird auf der Grafikkarte dann Szenenunabhängig ungefähr ein Bereich von 500 Megabyte genutzt.
Und ja- Das war kein Vertipper. Megabyte, nicht Gigabyte.
Letztendlich ist Sampler Feedback Streaming der Horror für alle Grafikkartenhersteller, die meinen sich ihren VRAM auf den Karten mit dem Kaufpreis "vergolden" zu lassen. Und jetzt fragt sich nochmal einer, warum diese revolutionäre Technik noch keinen Einzug in die Spieleengines/Software findet")
Den VRAM kaufen die Grafikkartenhersteller auch nur ein. Ihn nicht mehr kaufen zu müssen und stattdessen die volle Gewinnspanne auf die GPU zu verschieben, wäre deren Traum. Genau deswegen pusht Nvidia die Technik doch.
Aber von 4K in 0,5G sind wir, nicht nur am PC, meilenweit entfernt. Rapid-81 berichtet oben, dass RTX IO die ab-Laufwerk-Streaming-Leistung von 2,3 GB/s auf 12 GB/s steigert. Das mag wie eine gigantische Leistungssteigerung klingen, aber bei intelligenter RAM-Nutzung werden Daten derzeit mit 32 GB/s nachgeliefert; ab der nächsten GPU-Generation hoffentlich mit 64 GB/s. Dagegen ist auch Rapid Storage so wenig, dass man andere, bestehende Lösungen nutzen muss, wenn man die Grafik weiterentwickeln möchte. (Ich befürchte, dass es einige Entwickler trotzdem sein lassen werden und uns eine Reihe von Konsolenports mit mieserer Performance und/oder Grafik als bislang erwartet.)
Und eine Reduktion des VRAMs auf Framebuffer ist komplett utopisch. Eine RTX 4090 rendert aus 1.008 GB/s, um das zu ersetzen müsste die Streaming-Leistung gegenüber jetzt um den Faktor 100 steigen und zusätzlich noch die Latenz extrem reduziert werden. Gegen solche Phantasien mutet ein Ersatz des Systems-RAMs durch ungepuffertes Streaming vom Laufwerk in den RAM geradezu plausibel an. In der Praxis kommt aber eben selbst da eine verkrüppelte Konsole bei raus und den RAM wegzulassen werden sehr viele PC-Anwendungen gar nicht mögen.
Zuletzt bearbeitet:





.gif "sm_B-) :-)")

.gif "sm_=) =)")
