Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
AMD CPUs: Speicher-Flaschenhals von MCM-CPUs soll durch ausgelagerte Northbridge umgangen werden
Die Synthese von Mesh-of-Trees ist jedoch anders wie diese von Ring On-Chip. Hierunter wird auch erklärt, wie die früheren Multicore-Chips mit zunehmender Kernzahl sich über den Ring On-Chip Interconnect verbunden haben. Schnell wird klar, dass sich daraus Einbahnstraßen und Staus bilden. Der Mesh-of-Trees Interconnect scheint dieses Problem gelöst zu haben, wie die Grafik zeigt. Intel Skylake-SP: Mesh statt Ringbus | heise online
Es bleibt abzuwarten, was Intels anstehendes Hybrid-Interface "High-Performance Hierarchical Ring On-Chip Interconnect" den etablierten Kommunikationsschnittstellen entgegen zu setzen hat, ob die Nachteile beider Systeme sich aufwiegen zugunsten ihrer Vorteile.
Momentan ist nicht einmal zugesichert, wann und womit der High-Performance Hierarchical Ring On-Chip Interconnect und ebenso der UltraPath Interconnect eingeführt werden. Zuerst ging die Gerüchteküche von Cascade Lake-SP aus, nun ist es nicht einmal mit Gewissheit zu sagen, ob es denn noch vor Ice Lake-SP wird.
Das stimmt durchaus.
Figure #5 und #6 zeigen, wie der Ansatz aussehen soll: A High-Performance Hierarchical Ring On-Chip Interconnect with Low-Cost Routers - Semantic Scholar
Man erkennt die Gitterstruktur in Figure #6, diese die Cluster einigt, und zu Figure #5 die Ringstruktur, diese dann die primäre Kommunikation zu sein scheint. Der Mesh-Ansatz funktioniert also nicht primär wie im Falle von Skylake-SP und so weiter. Der Name dieses Intercores verrät 's ja eigentlich schon im Ansatz, wie 's gedacht sein soll.
Ihr seid aber lustig
Deutsch ist auch nur etwa meine 4. Sprache die ich lerne und ich bilde mir ein... hmmm... ich wage zu behaupten, dass ich mich meist leserlicher ausdrücke
Ihr seid aber lustig
Deutsch ist auch nur etwa meine 4. Sprache die ich lerne und ich bilde mir ein... hmmm... ich wage zu behaupten, dass ich mich meist leserlicher ausdrücke
Ich bin jetzt echt gespannt, was AMD uns zeigen wird.
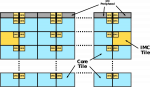
Bis jetzt verstehe ich das Ganze als eine, für das Betriebssytem, Ein-Prozessorarchitektur mit vorgelagertem Speichercontroller für alle Recheneinheiten und aus diesem Gedanken und gelöst von den Schaubildern, sehe ich da nicht zwangsweise Verschelchterungen.
Ich wäre wirklich etwas enttäuscht, wenn AMD jetzt mit schlechteren, mittleren Latenzen käme,
zumal ja auch Verbesserungen am IF angekündigt wurden, wie auch schon bei Zen+ und die Schaubilder sind ja auch nur Spekulation, leider.
Die Zugriffe die früher innerhalb eines CCX stattgefunden haben und bei etwa der Hälfte der NS über die Fabric lagen, könnten sich verdoppeln oder erhöhen.
Wenn dafür UMA statt NUMA kommt ist das aber für den Servermarkt auf jeden Fall ein Vorteil.
Für den Desktopmarkt könnte es eine Bremse sein.
Bin gespannt wie sich der Ansatz von Intels Mesh unterscheidet.
Ihr seid aber lustig
Deutsch ist auch nur etwa meine 4. Sprache die ich lerne und ich bilde mir ein... hmmm... ich wage zu behaupten, dass ich mich meist leserlicher ausdrücke
Die Zugriffe die früher innerhalb eines CCX stattgefunden haben und bei etwa der Hälfte der NS über die Fabric lagen, könnten sich verdoppeln oder erhöhen.
Sorry, ich verstehe nicht, was du meinst. Was soll sich erhöhen? Wenn die CCX Module größer werden, dann ist eine größere Threadgruppierung möglich -> Optimierung.



")
